
Anthropic just shipped Claude Sonnet 5. They call it its most agentic Sonnet model yet. It plans, drives browsers and terminals, and runs autonomously across long tasks.
Sonnet 5 is the default model for Free and Pro plans today. Max, Team, and Enterprise users can select it. It is also live in Claude Code and on the Claude Platform.
TL;DR
- Sonnet 5 is Anthropic’s most agentic mid-tier model, closing much of the gap to Opus 4.8.
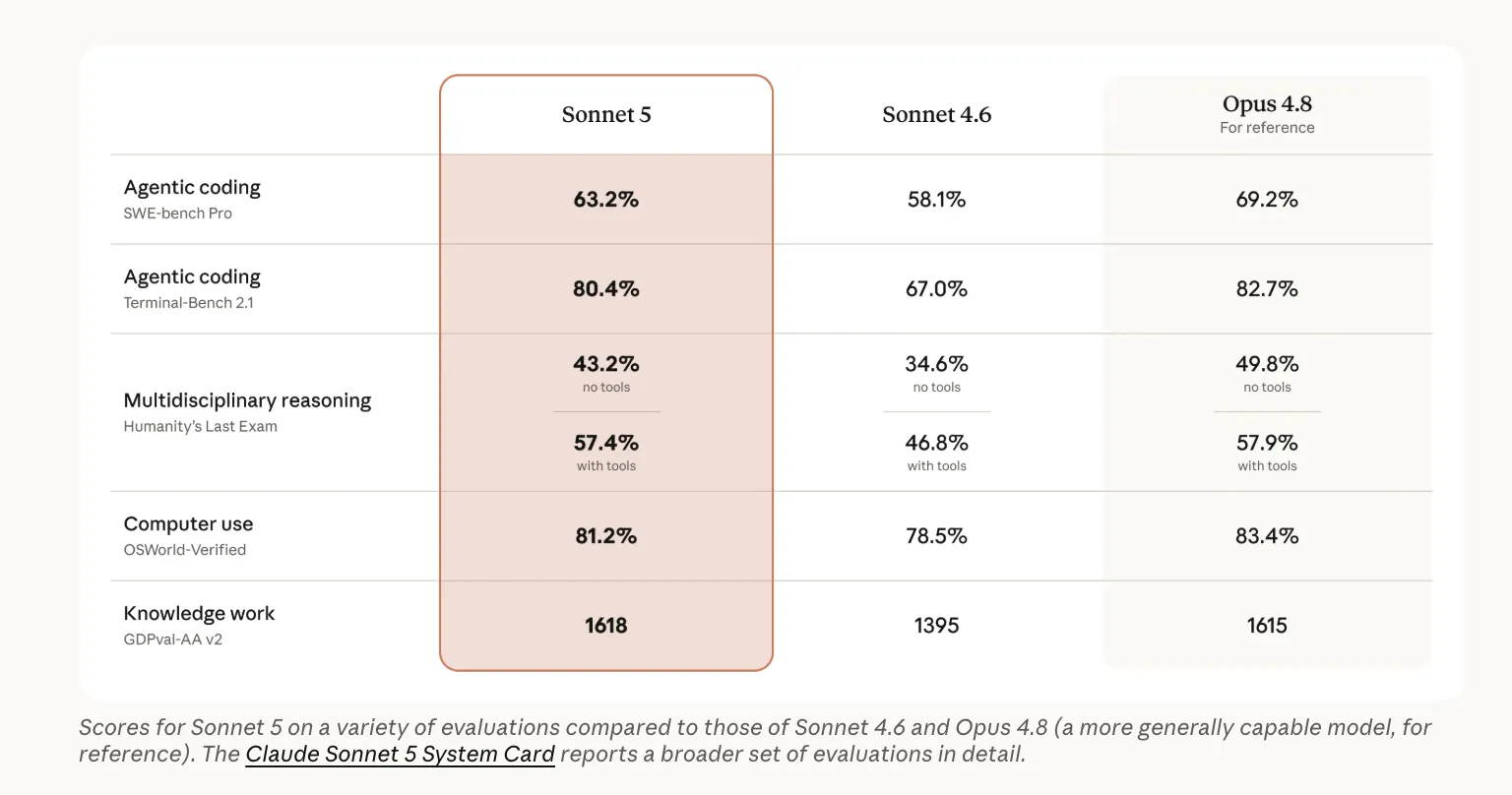
- Beats Sonnet 4.6 on every published benchmark: 63.2% SWE-bench Pro, 81.2% OSWorld-Verified, 57.4% HLE.
- Cheaper to run: $2/$10 per MTok intro pricing through Aug 31, then $3/$15; Opus 4.8 is $5/$25.
- Best value at low/medium effort; at xhigh it can cost more than Opus 4.8 for similar quality.
- Safer than 4.6, with deliberately low cyber capability — Opus stays the pick for accuracy-critical work.
Claude Sonnet 5
Sonnet sits in the middle of Anthropic’s lineup. It is above the cheaper Haiku 4.5 and below the flagship Opus 4.8.
Sonnet 5 is an upgrade to Sonnet 4.6, which launched in February 2026. Anthropic frames this release around agentic reliability, not one headline benchmark.
In practice, that means longer task chains without losing context. It means better self-correction when a tool call fails. It means steadier behavior across extended sessions inside Claude Code or Cowork.
The model exposes effort levels: low, medium, high, and xhigh (extra high). Higher effort spends more tokens on reasoning. That raises both quality and cost.
It is important to note that Sonnet 5 uses an updated tokenizer, the same one introduced with Opus 4.7. The same text can map to roughly 1.0 to 1.35 times more tokens.
Interactive Explainer
Claude Sonnet 5 — Cost & Capability Explorer
Estimate per-task cost across models and compare published benchmarks. All figures from Anthropic’s June 30, 2026 launch.
Per-task cost estimator
$0.00
per task • $0.00/day • $0.00/mo
Sonnet 5 uses an updated tokenizer (same as Opus 4.7). The same text can map to roughly 1.0–1.35× more tokens, so the factor is applied to Sonnet 5 only.
Published benchmark comparison
Sonnet 4.6
Sonnet 5
Opus 4.8
On knowledge work (GDPval-AA v2), Sonnet 5 scores 1,618 and edges Opus 4.8’s 1,615. That benchmark uses a different scale, so it is shown here as a note rather than a bar.
Benchmark
Anthropic team published a benchmark table comparing Sonnet 5, Sonnet 4.6, and Opus 4.8. Sonnet 5 beats its predecessor in every tested category. It closes much of the gap to Opus 4.8.
On agentic coding (SWE-bench Pro), Sonnet 5 scores 63.2%. Sonnet 4.6 scored 58.1%. Opus 4.8 still leads at 69.2%.
On computer use (OSWorld-Verified), Sonnet 5 posts 81.2% against Sonnet 4.6’s 78.5%. On Terminal-Bench 2.1, it reaches 80.4% versus 67.0%.
On Humanity’s Last Exam with tools, Sonnet 5 hits 57.4%. That nearly matches Opus 4.8 at 57.9%.
There is one place where Sonnet 5 edges ahead. On the GDPval-AA v2 knowledge-work benchmark, it scores 1,618 against Opus 4.8’s 1,615.
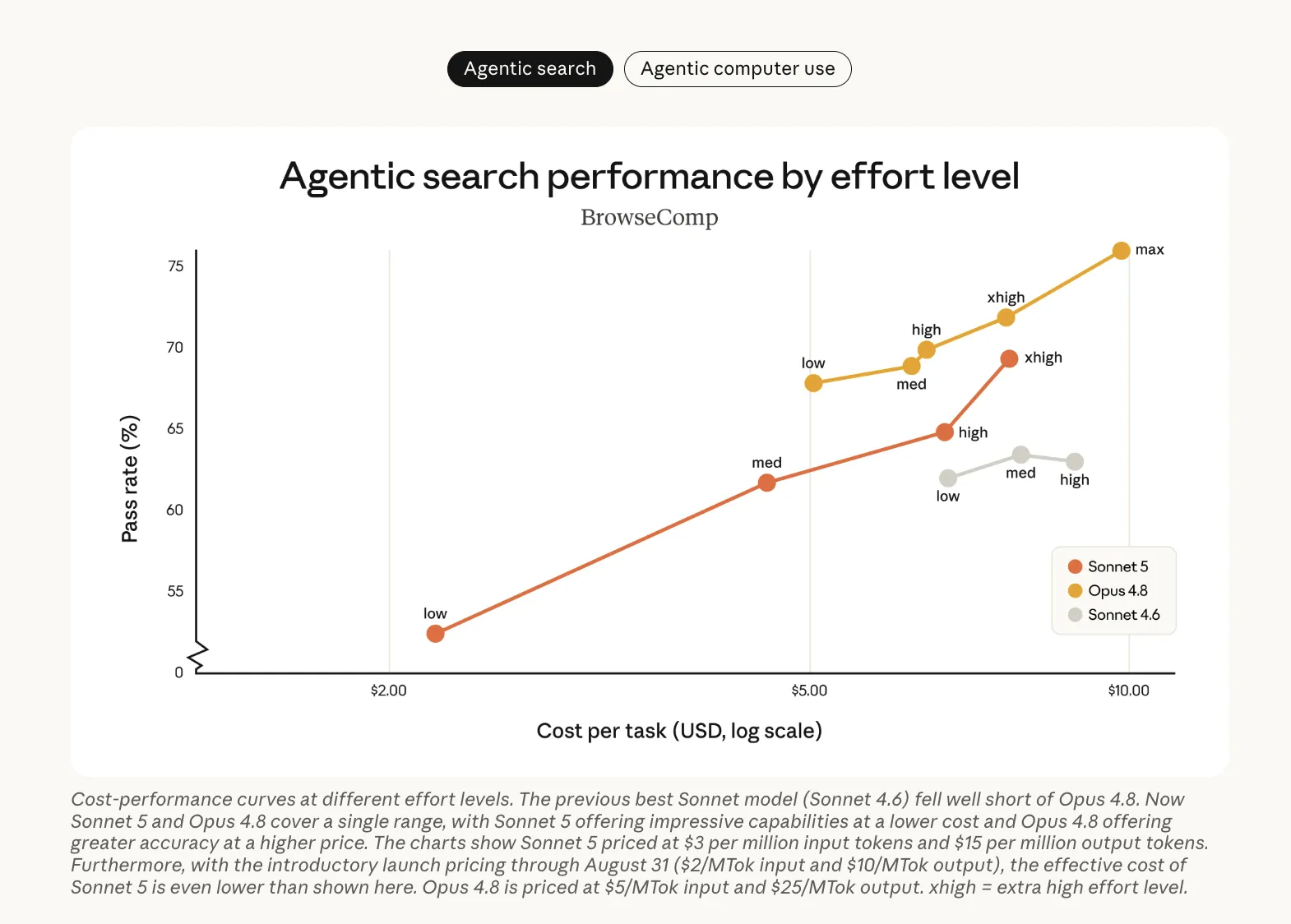
Effort Levels: Where the Real Tradeoff Lives
The cost-performance story is the most important part for developers. Sonnet 5 is a strict improvement over Sonnet 4.6 across every effort level. The clearest value appears at low and medium effort.
At those levels, Sonnet 5 delivers quality that earlier Sonnet pricing could not buy. Opus 4.8 remains the accuracy leader at the top of the range.
A practical routing policy follows from this. Send most agentic coding, tool use, and knowledge work to Sonnet 5. Reserve Opus 4.8 for accuracy-critical tasks. Keep Haiku 4.5 for high-volume, latency-sensitive calls.
Use Cases: Where Sonnet 5 Fits
Early access partners described concrete workflows. Their reports map to common engineering jobs.
- Multi-step software engineering: One tester asked Sonnet 5 to investigate a bug. It wrote a reproducing test, implemented the fix, then confirmed the bug returned without the change. It did this in a single pass.
- Brownfield debugging: Another partner ran it on hard pull requests. The model traced failures to their root causes. It shipped durable fixes rather than symptom patches.
- Business automation: Zapier handed it a two-part job. It updated Salesforce account tiers, then sent a launch email to enterprise contacts. It finished the task end to end.
- Computer-use agents: Pace runs insurance workflows like submission intake and loss runs. Its agents act on the operational systems teams already use.
- Data exploration: ClickHouse agents query live data and produce insights on the fly. Faster reasoning means faster time-to-insight for analysts.
Comparison Table
| Metric / Spec | Sonnet 4.6 | Sonnet 5 | Opus 4.8 |
|---|---|---|---|
| Agentic coding (SWE-bench Pro) | 58.1% | 63.2% | 69.2% |
| Terminal-Bench 2.1 | 67.0% | 80.4% | not reported |
| Computer use (OSWorld-Verified) | 78.5% | 81.2% | not reported |
| Humanity’s Last Exam (with tools) | 46.8% | 57.4% | 57.9% |
| Knowledge work (GDPval-AA v2) | not reported | 1,618 | 1,615 |
| Input price ($/MTok) | 3 | 2 intro, then 3 | 5 |
| Output price ($/MTok) | 15 | 10 intro, then 15 | 25 |
Sonnet 5’s introductory pricing runs through August 31, 2026. Standard pricing of $3/$15 begins after that date. Standard prompt caching (cache reads at 0.1x input) and the 50% Batch API discount also apply. Per token, Sonnet 5 undercuts GPT-5.5 and Gemini 3.1 Pro, but costs more than Gemini 3.5 Flash. Anthropic lists a 1M-token context window for Sonnet 5 in its launch post. It does not publish context figures for the other models here.
Coding Example: Calling Sonnet 5
The API call mirrors any other Anthropic model. You change the model string to claude-sonnet-5.
import anthropic
client = anthropic.Anthropic() # reads ANTHROPIC_API_KEY
message = client.messages.create(
model="claude-sonnet-5",
max_tokens=1024,
messages=[
{"role": "user", "content": "Find the race condition in worker.py and ship a tested fix."}
],
)
print(message.content[0].text)Strengths and Weaknesses
Strengths:
- Improves on Sonnet 4.6 in every benchmark category Anthropic tested
- Near-Opus 4.8 quality on several evaluations, at lower per-token prices
- Edges Opus 4.8 on the GDPval-AA v2 knowledge-work benchmark
- Lower hallucination, sycophancy, and undesirable-behavior rates than Sonnet 4.6
- Drop-in API change: you only swap the model string
Weaknesses:
- Opus 4.8 still wins on the hardest accuracy-critical tasks
- At xhigh effort, cost can exceed Opus 4.8 at similar quality
- The new tokenizer can raise token counts by up to 1.35 times
- Cyber capability is intentionally low; use Opus for sanctioned cyber work
- Standard pricing of $3/$15 arrives after August 31, 2026
Claude Sonnet 5 — Community Reaction
Early developer reactions from Hacker News and X on launch day, June 30, 2026.
Sentiment of the 8 reactions shown
Positive · 38%
Neutral / mixed · 38%
Negative · 25%
Mixed reception: praise for price-to-value, doubts about standing at full $3/$15 pricing. Manually labeled from the public posts below; the two Reddit links are live threads, not counted here.
X@ClaudeDevs (official)Positive
“Top-tier performance on coding and tool use at Sonnet pricing” — with a 1M context window.
Hacker NewsphillipcarterPositive
“Another great incremental update to the workhorse.” Uses Sonnet over Opus for most coding.
Hacker NewsmchusmaMixed
Far more compelling at the $2/$10 launch price than at full standard pricing.
X@kimmonismusPositive
“Near Opus 4.8-level performance, but cheaper.” Strong gains in reasoning and tool use.
Hacker NewsandaiCritical
“If you’re doing something hard, just use a bigger model.” Opus wins parts of the frontier.
Hacker NewsconradkayCritical
“Seems worse even on price/performance than GLM 5.2” at 744B parameters.
Hacker Newsmag7269Neutral
“When can we get a new Haiku?” 4.5 is nearly a year old and showing its age.
Hacker NewsbredrenMixed
Sees the value clearly at low and medium effort; less so at high versus Opus 4.8.
Redditr/ClaudeAI
Launch-day discussion — benchmarks, pricing, and Claude Code impressions from the community.
Redditr/LocalLLaMA
Open-weights vs. Sonnet 5 price/performance debate, with GLM-5.2 and K2.7 comparisons.
Reddit cards link to live launch-day subreddits, since a single canonical thread was still forming at publish time. Hacker News and X cards quote specific, linkable public posts. Sentiment labels are a manual editorial read, not an automated score.
Check out the Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us




")

