
Zyphra has released Zamba2-VL, a family of open vision-language models. The release covers three sizes: 1.2B, 2.7B, and 7B parameters. Each model is built on the Zamba2 hybrid SSM–Transformer backbone.
Vision-language models (VLMs) read images and text together. They answer questions about charts, documents, and photos. Most open VLMs use a dense Transformer as the language model. Zamba2-VL replaces that with a hybrid state-space design. The goal is competitive accuracy at lower latency.
What is Zamba2-VL
Zamba2-VL follows the now-standard LLaVA-style VLM template. A pre-trained vision encoder turns image patches into features. A lightweight MLP adapter projects those features into the language model’s space. The language model then reads an interleaved sequence of vision and text tokens. The models support single and multi-image understanding and grounding.
Zyphra pairs each Zamba2 backbone with the Vision Transformer from Qwen2.5-VL. That encoder was chosen for two specific properties. It uses 2D rotary position embeddings and native dynamic-resolution processing. A two-layer MLP adapter connects the encoder to the backbone.
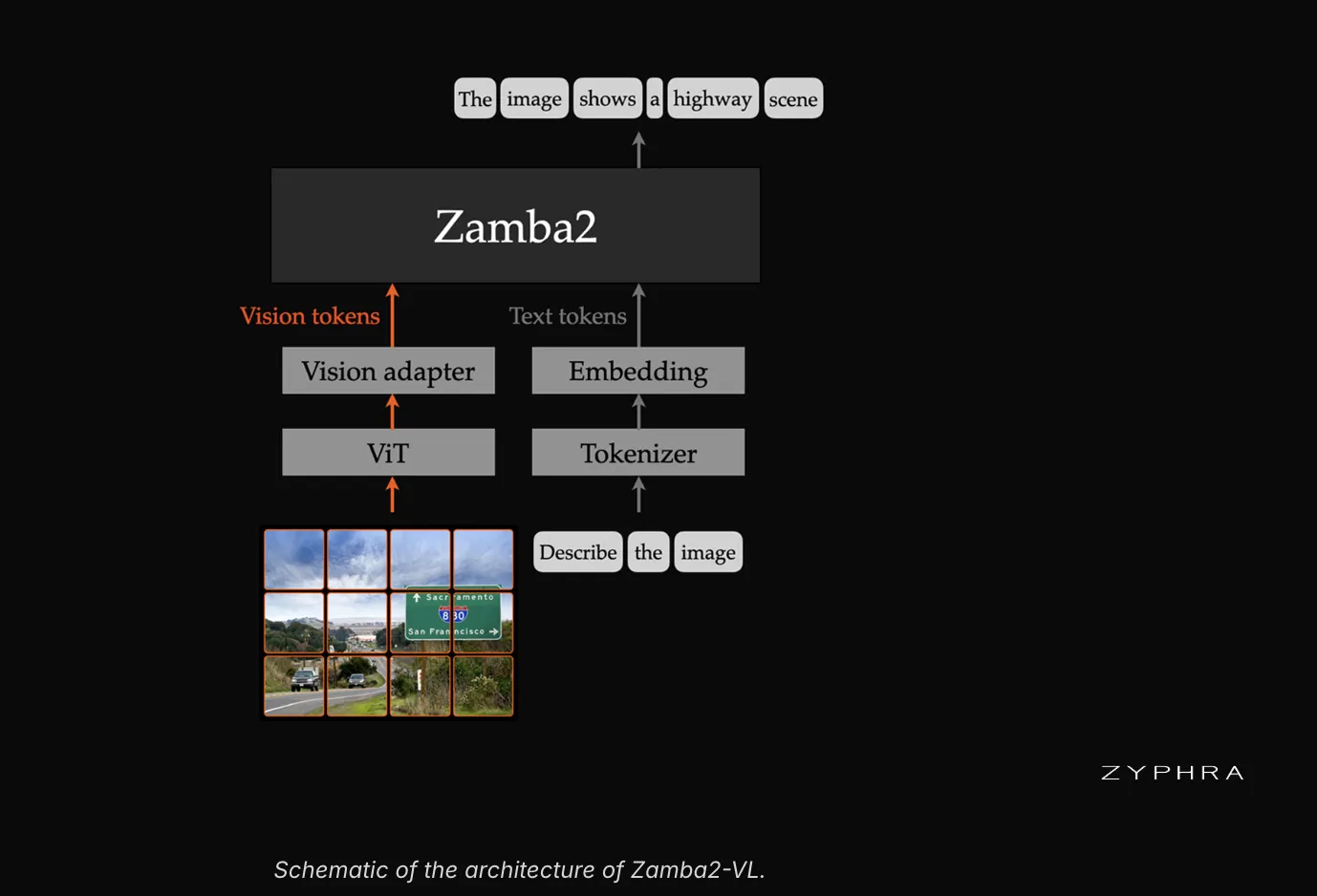
The Architecture
The Zamba2’s backbone is where the design diverges from typical VLMs. It is a hybrid of Mamba2 state-space layers and shared transformer blocks. The Mamba2 layers run in linear time with a fixed-size state. A small number of shared attention layers are interleaved between them. Each shared block carries a unique LoRA adapter at each layer.
The Mamba2 layers carry the bulk of computation cheaply. The shared attention layers preserve in-context retrieval that pure-SSM models give up. The hybrid trades full-attention expressivity against state-space efficiency.
Zamba2-VL uses the Mistral v0.1 tokenizer. It was trained on 100B tokens of vision-text and pure-text data. That data was sourced from open web datasets.
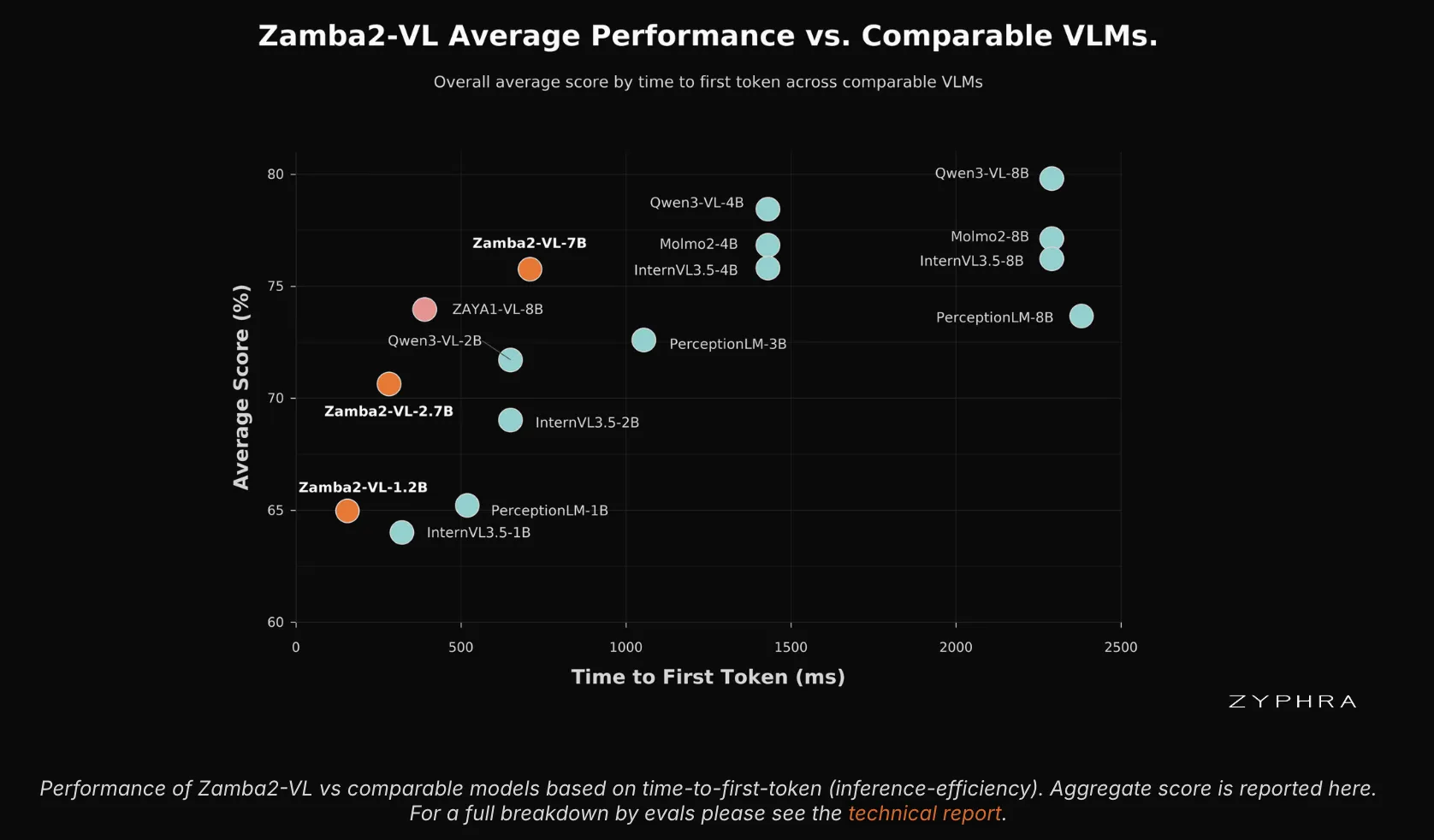
Model Quality and Benchmarks
The research team evaluated Zamba2-VL across 14 benchmarks. These span chart, diagram, and document understanding. They also cover general perception, reasoning, and visual counting. All scores come from Zyphra’s evaluation harness, which is based on VLMEvalKit. The report compares against the Molmo2, Qwen3-VL, and InternVL3.5 families.
| Eval | Zamba2-VL-2.7B | InternVL3.5-2B | Qwen3-VL-2B | Molmo2-4B | Qwen3-VL-4B |
|---|---|---|---|---|---|
| DocVQA (test) | 90.9 | 89.4 | 93.3 | 87.8 | 95.3 |
| ChartQA (test) | 79.6 | 81.6 | 78.7 | 86.1 | 81.8 |
| OCRBench | 73.6 | 83.4 | 84.1 | 62.0 | 84.1 |
| CountBenchQA | 87.5 | 70.0 | 87.9 | 91.2 | 87.3 |
| PixMoCount (test) | 82.5 | 32.8 | 55.7 | 87.0 | 89.2 |
| MMMU (val) | 37.7 | 49.9 | 40.9 | 48.8 | 51.4 |
| MathVista (mini) | 51.0 | 61.4 | 51.8 | 56.5 | 63.6 |
InternVL3.5-2B and Qwen3-VL-2B are similar in size. Molmo2-4B and Qwen3-VL-4B are larger.
The pattern is uneven and worth understanding. Counting is the strongest category. Zyphra reports Zamba2-VL-1.2B at 62.5 on PixMoCount. That compares with 32.8 for InternVL3.5-1B and 17.7 for PerceptionLM-1B. Document understanding also holds up, with DocVQA at 90.9 for the 2.7B model. The model lags larger baselines on knowledge-heavy reasoning, such as MMMU and MathVista.
Why Inference is Faster
Inference is where Zamba2-VL shows its main advantage. Transformer attention scales quadratically with sequence length. Multimodal inputs make sequences long very quickly. A single high-resolution image can add several thousand vision tokens. A short video clip can produce tens of thousands of tokens.
Zamba2-VL avoids the growing KV cache of attention. It inherits near-linear-time prefill and a fixed-size recurrent state. On a 32k-token prefill, it leads on the score-versus-TTFT plot. No Transformer VLM in the comparison matched its score at similar latency. The latency gap is at least an order of magnitude.
The efficiency advantage is largest at the 1.2B and 2.7B scales. That is the range targeted for on-device and edge deployment.
Use Cases With Examples
The practical question is where this fits. Document and form extraction benefits from the strong DocVQA results. Think invoice parsing or receipt digitization at scale. Retail and inventory counting maps to the PixMoCount and CountBenchQA strengths. Grounding support enables pointing to objects in product or UI images. On-device assistants benefit from the low time-to-first-token. The 1.2B model targets phones and edge boxes. Long visual inputs, like multi-page PDFs, gain most from linear-time prefill.
Getting Started
The three models live in the Zyphra Zamba2-VL collection on Hugging Face. Inference runs through Zyphra’s transformers fork, based on transformers v4.57.1. The optimized Mamba2 kernels need a CUDA GPU for good latency.
Install the fork and its core dependencies:
pip install "transformers @ git+https://github.com/Zyphra/transformers.git@zamba2-vl"
pip install qwen-vl-utils==0.0.2
pip install flash_attnOptimized Mamba2 kernels need two more packages:
pip install --no-build-isolation "causal-conv1d @ git+https://github.com/Zyphra/z-causal-conv1d.git@zamba2-vl"
pip install --no-build-isolation "mamba-ssm @ git+https://github.com/Zyphra/mamba.git@zamba2-vl"Then load the model and run a single-image query:
from transformers import Zamba2_VLForConditionalGeneration, Zamba2_VLProcessor
import torch
from PIL import Image
from qwen_vl_utils import process_vision_info
import requests
device = "cuda"
processor = Zamba2_VLProcessor.from_pretrained("Zyphra/Zamba2-VL-2.7B", temporal_patch_size=1)
model = Zamba2_VLForConditionalGeneration.from_pretrained(
"Zyphra/Zamba2-VL-2.7B",
device_map=device,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
question = "What do you see in the image? Give us some detail."
num_img_tokens = 3400
conversation = [
{"role": "user", "content": [
{"type": "image", "image": image,
"max_pixels": num_img_tokens * 28 * 28, "min_pixels": 10 * 28 * 28},
{"type": "text", "text": question},
]},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
images, _ = process_vision_info(conversation)
inputs = processor(text=prompt, images=images, add_special_tokens=True, return_tensors="pt")
inputs = {key: value.to(device) for key, value in inputs.items()}
outputs = model.generate(**inputs, max_new_tokens=100)
print(processor.tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))Swap the model ID for Zamba2-VL-1.2B or Zamba2-VL-7B to change scale.
Strengths and Weaknesses
Strengths:
- First open VLM family on a fully open hybrid SSM–Transformer LLM, per Zyphra.
- About an order of magnitude lower time-to-first-token than comparable Transformer baselines.
- Strong visual counting and competitive document understanding.
- Three sizes cover edge, mid, and 7B-class deployment.
- Apache 2.0 license with public weights and working inference code.
Weaknesses and Challenges:
- Released as a research artifact.
- Lags larger models on knowledge reasoning like MMMU and MathVista.
- Lower OCRBench than same-size Qwen3-VL and InternVL3.5.
- Optimized kernels need a CUDA GPU; CPU paths are slow.
- Deployment requires self-hosting from the released code.
Key Takeaways
- Zamba2-VL ships at 1.2B, 2.7B, and 7B parameters under Apache 2.0.
- The backbone pairs Mamba2 state-space layers with a few shared transformer blocks.
- Time-to-first-token drops about an order of magnitude versus comparable Transformer VLMs.
- Counting and document understanding are strengths; knowledge reasoning lags.
- Weights and working inference code are public on Hugging Face and GitHub.
Marktechpost’s Interactive Explainer
Interactive Explainer
Zamba2-VL: Hybrid SSM–Transformer Vision-Language Models
Open VLMs at 1.2B, 2.7B, and 7B that replace dense attention with a Mamba2 state-space + Transformer hybrid. Apache 2.0.
The pipeline (tap a stage)
Zamba2-VL follows the LLaVA-style template: vision encoder → adapter → language model.
Token-scaling lab
Drag the slider or pick a preset. Attention prefill scales O(n²); the Mamba2 layers scale O(n).
3,400 vision tokensabout one high-resolution image
At this length, the hybrid uses about 1.0× less prefill compute
Measured claim: Zyphra reports near-linear-time prefill and a fixed-size recurrent state. On a 32k-token prefill, it reports roughly an order-of-magnitude lower time-to-first-token than the closest Transformer baseline.
Bars above illustrate O(n²) vs O(n) scaling, not measured latency.
Benchmark explorer — Zamba2-VL-2.7B vs baselines
Pick an eval. Green is Zamba2-VL-2.7B. Higher is better.
Source: Zyphra evaluation harness (VLMEvalKit). InternVL3.5-2B and Qwen3-VL-2B are similar in size; Molmo2-4B and Qwen3-VL-4B are larger.
Check out the Paper, GitHub Repo, Model weights and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us







