
IBM researchers, together with ETH Zürich, have unveiled a new class of Analog Foundation Models (AFMs) designed to bridge the gap between large language models (LLMs) and Analog In-Memory Computing (AIMC) hardware. AIMC has long promised a radical leap in efficiency—running models with a billion parameters in a footprint small enough for embedded or edge devices—thanks to dense non-volatile memory (NVM) that combines storage and computation. But the technology’s Achilles’ heel has been noise: performing matrix-vector multiplications directly inside NVM devices yields non-deterministic errors that cripple off-the-shelf models.
Why does analog computing matter for LLMs?
Unlike GPUs or TPUs that shuttle data between memory and compute units, AIMC performs matrix-vector multiplications directly inside memory arrays. This design removes the von Neumann bottleneck and delivers massive improvements in throughput and power efficiency. Prior studies showed that combining AIMC with 3D NVM and Mixture-of-Experts (MoE) architectures could, in principle, support trillion-parameter models on compact accelerators. That could make foundation-scale AI feasible on devices well beyond data-centers.
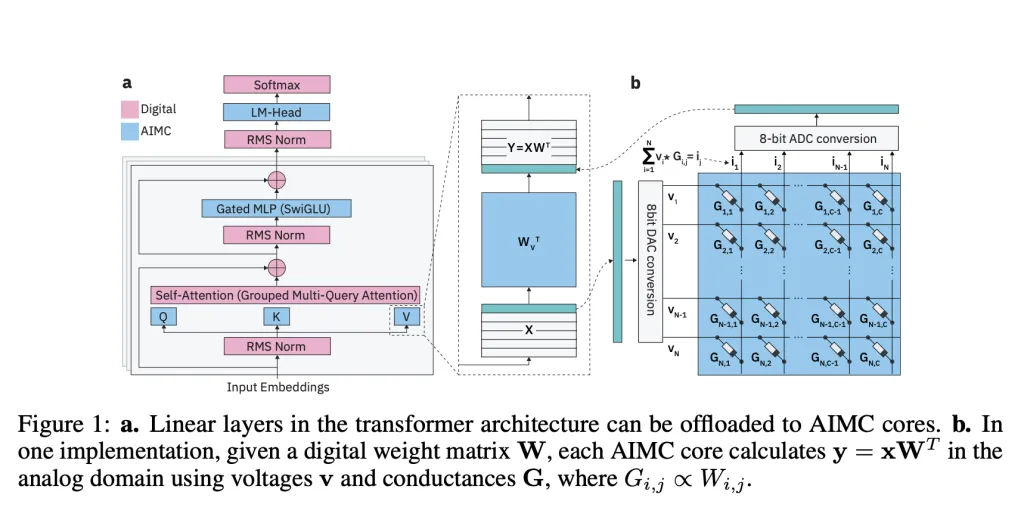
What makes Analog In-Memory Computing (AIMC) so difficult to use in practice?
The biggest barrier is noise. AIMC computations suffer from device variability, DAC/ADC quantization, and runtime fluctuations that degrade model accuracy. Unlike quantization on GPUs—where errors are deterministic and manageable—analog noise is stochastic and unpredictable. Earlier research found ways to adapt small networks like CNNs and RNNs (<100M parameters) to tolerate such noise, but LLMs with billions of parameters consistently broke down under AIMC constraints.
How do Analog Foundation Models address the noise problem?
The IBM team introduces Analog Foundation Models, which integrate hardware-aware training to prepare LLMs for analog execution. Their pipeline uses:
- Noise injection during training to simulate AIMC randomness.
- Iterative weight clipping to stabilize distributions within device limits.
- Learned static input/output quantization ranges aligned with real hardware constraints.
- Distillation from pre-trained LLMs using 20B tokens of synthetic data.
These methods, implemented with AIHWKIT-Lightning, allow models like Phi-3-mini-4k-instruct and Llama-3.2-1B-Instruct to sustain performance comparable to weight-quantized 4-bit / activation 8-bit baselines under analog noise. In evaluations across reasoning and factual benchmarks, AFMs outperformed both quantization-aware training (QAT) and post-training quantization (SpinQuant).
Do these models work only for analog hardware?
No. An unexpected outcome is that AFMs also perform strongly on low-precision digital hardware. Because AFMs are trained to tolerate noise and clipping, they handle simple post-training round-to-nearest (RTN) quantization better than existing methods. This makes them useful not just for AIMC accelerators, but also for commodity digital inference hardware.
Can performance scale with more compute at inference time?
Yes. The researchers tested test-time compute scaling on the MATH-500 benchmark, generating multiple answers per query and selecting the best via a reward model. AFMs showed better scaling behavior than QAT models, with accuracy gaps shrinking as more inference compute was allocated. This is consistent with AIMC’s strengths—low-power, high-throughput inference rather than training.
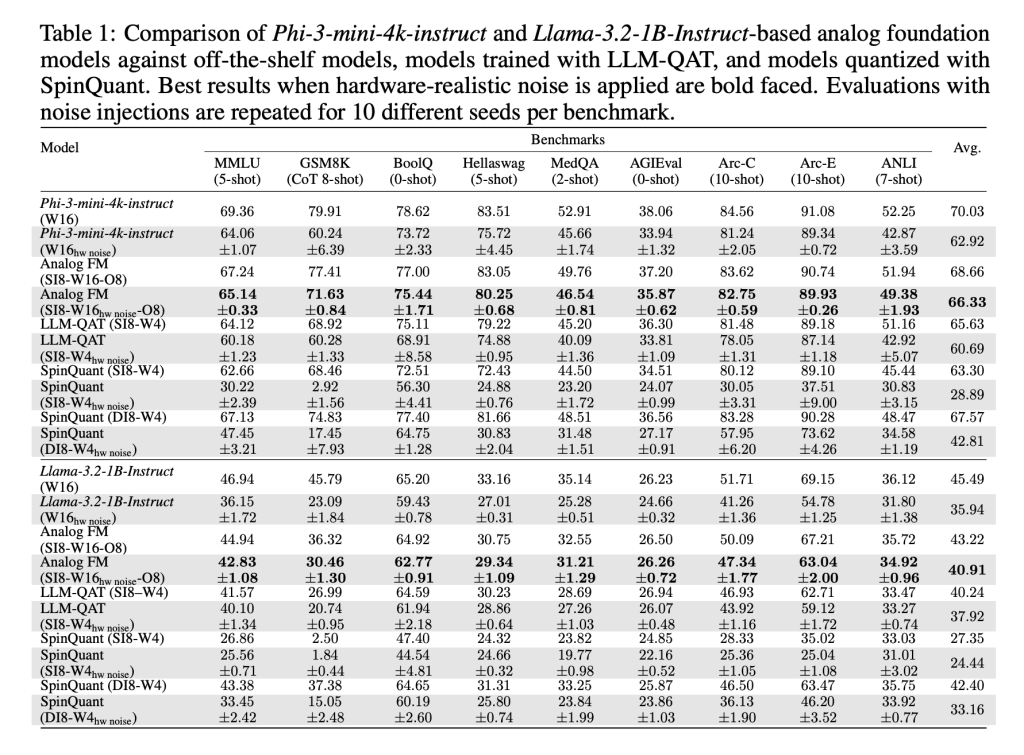
How does it impact Analog In-Memory Computing (AIMC) future?
The research team provides the first systematic demonstration that large LLMs can be adapted to AIMC hardware without catastrophic accuracy loss. While training AFMs is resource-heavy and reasoning tasks like GSM8K still show accuracy gaps, the results are a milestone. The combination of energy efficiency, robustness to noise, and cross-compatibility with digital hardware makes AFMs a promising direction for scaling foundation models beyond GPU limits.
Summary
The introduction of Analog Foundation Models marks a critical milestone for scaling LLMs beyond the limits of digital accelerators. By making models robust to the unpredictable noise of analog in-memory computing, the research team shows that AIMC can move from a theoretical promise to a practical platform. While training costs remain high and reasoning benchmarks still show gaps, this work establishes a path toward energy-efficient large scale models running on compact hardware, pushing foundation models closer to edge deployment
Check out the PAPER and GITHUB PAGE. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.







