
AI has the potential to make expert medical reasoning more accessible, but current evaluations often fall short by relying on simplified, static scenarios. Real clinical practice is far more dynamic; physicians adjust their diagnostic approach step by step, asking targeted questions and interpreting new information as it comes. This iterative process helps them refine hypotheses, weigh costs and benefits of tests, and avoid jumping to conclusions. While language models have shown strong performance on structured exams, these tests don’t reflect the real-world complexity, where premature decisions and over-testing remain serious concerns often missed by static assessments.
Medical problem-solving has been explored for decades, with early AI systems utilizing Bayesian frameworks to guide sequential diagnoses in specialties such as pathology and trauma care. However, these approaches faced challenges due to the need for extensive expert input. Recent studies have shifted toward using language models for clinical reasoning, often evaluated through static, multiple-choice benchmarks that are now largely saturated. Projects like AMIE and NEJM-CPC introduced more complex case material but still relied on fixed vignettes. While some newer approaches assess conversational quality or basic information gathering, few capture the full complexity of real-time, cost-sensitive diagnostic decision-making.
To better reflect real-world clinical reasoning, researchers from Microsoft AI developed SDBench, a benchmark based on 304 real diagnostic cases from the New England Journal of Medicine, where doctors or AI systems must interactively ask questions and order tests before making a final diagnosis. A language model acts as a gatekeeper, revealing information only when specifically requested. To improve performance, they introduced MAI-DxO, an orchestrator system co-designed with physicians that simulates a virtual medical panel to choose high-value, cost-effective tests. When paired with models like OpenAI’s o3, it achieved up to 85.5% accuracy while significantly reducing diagnostic costs.
The Sequential Diagnosis Benchmark (SDBench) was built using 304 NEJM Case Challenge scenarios (2017–2025), covering a wide range of clinical conditions. Each case was transformed into an interactive simulation where diagnostic agents could ask questions, request tests, or make a final diagnosis. A Gatekeeper, powered by a language model and guided by clinical rules, responded to these actions using realistic case details or synthetic but consistent findings. Diagnoses were evaluated by a Judge model using a physician-authored rubric focused on clinical relevance. Costs were estimated using CPT codes and pricing data to reflect real-world diagnostic constraints and decision-making.
The researchers evaluated various AI diagnostic agents on the SDBench and found that MAI-DxO consistently outperformed both off-the-shelf models and physicians. While standard models showed a tradeoff between cost and accuracy, MAI-DxO, built on o3, delivered higher accuracy at lower costs through structured reasoning and decision-making. For instance, it reached 81.9% accuracy at $4,735 per case, compared to off-the-shelf O3’s 78.6% at $7,850. It also proved robust across multiple models and held-out test data, indicating strong generalizability. The system significantly improved weaker models and helped stronger ones utilize resources more efficiently, reducing unnecessary tests through smarter information gathering.
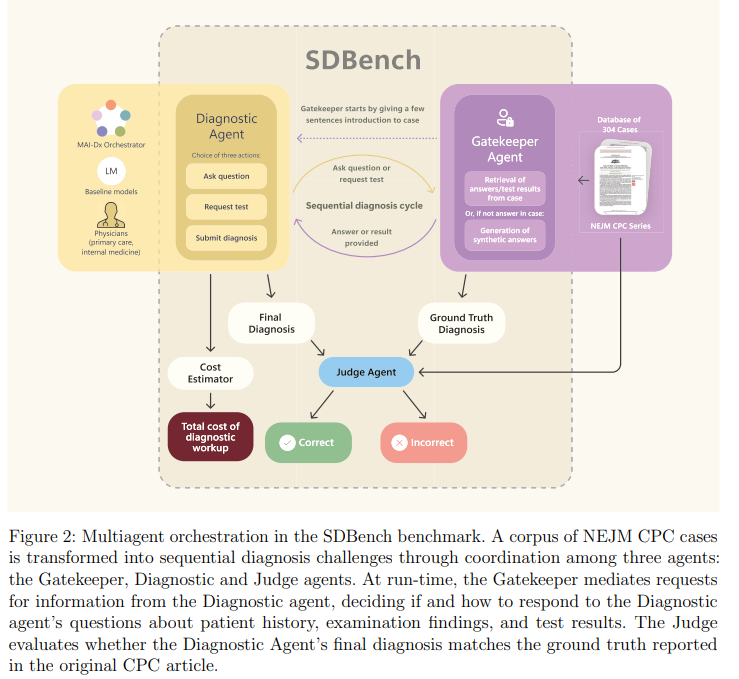
In conclusion, SDBench is a new diagnostic benchmark that turns NEJM CPC cases into realistic, interactive challenges, requiring AI or doctors to actively ask questions, order tests, and make diagnoses, each with associated costs. Unlike static benchmarks, it mimics real clinical decision-making. The researchers also introduced MAI-DxO, a model that simulates diverse medical personas to achieve high diagnostic accuracy at a lower cost. While current results are promising, especially in complex cases, limitations include a lack of everyday conditions and real-world constraints. Future work aims to test the system in real clinics and low-resource settings, with potential for global health impact and medical education use.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.




")


