
OpenAI introduced GDPval, a new evaluation suite designed to measure how AI models perform on real-world, economically valuable tasks across 44 occupations in nine GDP-dominant U.S. sectors. Unlike academic benchmarks, GDPval centers on authentic deliverables—presentations, spreadsheets, briefs, CAD artifacts, audio/video—graded by occupational experts through blinded pairwise comparisons. OpenAI also released a 220-task “gold” subset and an experimental automated grader hosted at evals.openai.com.
From Benchmarks to Billables: How GDPval Builds Tasks
GDPval aggregates 1,320 tasks sourced from industry professionals averaging 14 years of experience. Tasks map to O*NET work activities and include multi-modal file handling (docs, slides, images, audio, video, spreadsheets, CAD), with up to dozens of reference files per task. The gold subset provides public prompts and references; primary scoring still relies on expert pairwise judgments due to subjectivity and format requirements.
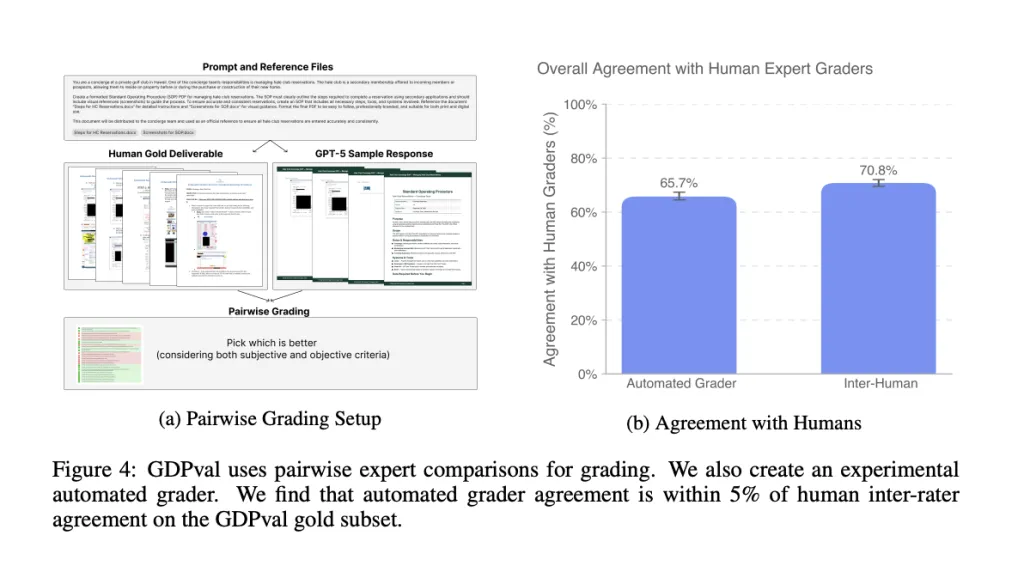
What the Data Says: Model vs. Expert
On the gold subset, frontier models approach expert quality on a substantial fraction of tasks under blind expert review, with model progress trending roughly linearly across releases. Reported model-vs-human win/tie rates near parity for top models, error profiles cluster around instruction-following, formatting, data usage, and hallucinations. Increased reasoning effort and stronger scaffolding (e.g., format checks, artifact rendering for self-inspection) yield predictable gains.
Time–Cost Math: Where AI Pays Off
GDPval runs scenario analyses comparing human-only to model-assisted workflows with expert review. It quantifies (i) human completion time and wage-based cost, (ii) reviewer time/cost, (iii) model latency and API cost, and (iv) empirically observed win rates. Results indicate potential time/cost reductions for many task classes once review overhead is included.
Automated Judging: Useful Proxy, Not Oracle
For the gold subset, an automated pairwise grader shows ~66% agreement with human experts, within ~5 percentage points of human–human agreement (~71%). It’s positioned as an accessibility proxy for rapid iteration, not a replacement for expert review.
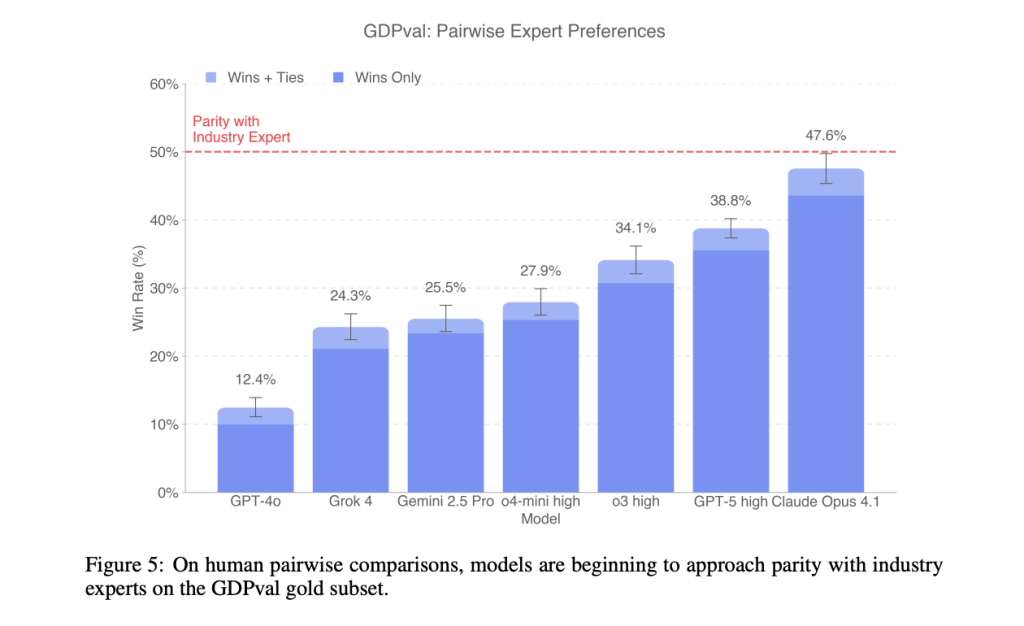
Why This Isn’t Yet Another Benchmark
- Occupational breadth: Spans top GDP sectors and a wide slice of O*NET work activities, not just narrow domains.
- Deliverable realism: Multi-file, multi-modal inputs/outputs stress structure, formatting, and data handling.
- Moving ceiling: Uses human preference win rate against expert deliverables, enabling re-baselining as models improve.
Boundary Conditions: Where GDPval Doesn’t Reach
GDPval-v0 targets computer-mediated knowledge work. Physical labor, long-horizon interactivity, and organization-specific tooling are out of scope. Tasks are one-shot and precisely specified; ablations show performance drops with reduced context. Construction and grading are resource-intensive, motivating the automated grader—whose limits are documented—and future expansion.
Fit in the Stack: How GDPval Complements Other Evals
GDPval augments existing OpenAI evals with occupational, multi-modal, file-centric tasks and reports human preference outcomes, time/cost analyses, and ablations on reasoning effort and agent scaffolding. v0 is versioned and expected to broaden coverage and realism over time.
Summary
GDPval formalizes evaluation for economically relevant knowledge work by pairing expert-built tasks with blinded human preference judgments and an accessible automated grader. The framework quantifies model quality and practical time/cost trade-offs while exposing failure modes and the effects of scaffolding and reasoning effort. Scope remains v0—computer-mediated, one-shot tasks with expert review—yet it establishes a reproducible baseline for tracking real-world capability gains across occupations.
Check out the Paper, Technical details, and Dataset on Hugging Face. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.







