 64x Better at Planning, Achieving 94% Accuracy")
Can a 8B-parameter language model produce provably valid multi-step plans instead of plausible guesses? MIT CSAIL researchers introduce PDDL-INSTRUCT, an instruction-tuning framework that couples logical chain-of-thought with external plan validation (VAL) to lift symbolic planning performance of LLMs. On PlanBench, a tuned Llama-3-8B reaches 94% valid plans on Blocksworld, with large jumps on Mystery Blocksworld and Logistics; across domains they report up to a 66% absolute improvement over baselines.
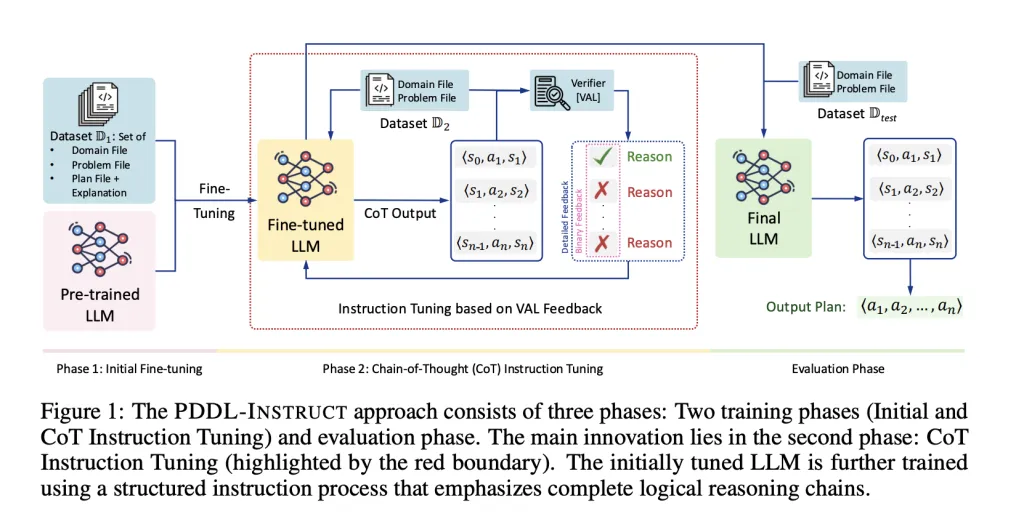
But What’s new?
The research team tackles a well-known failure mode: LLMs often generate “plausible-sounding” but logically invalid multi-step plans. PDDL-INSTRUCT couples explicit state/action semantics with ground-truth checking:
- Error education: Models are trained to explain why candidate plans fail (unsatisfied preconditions, wrong effects, frame violations, or goal not reached).
- Logical chain-of-thought (CoT): Prompts require step-by-step inference over preconditions and add/del effects, yielding state→action→state traces ⟨sᵢ, aᵢ₊₁, sᵢ₊₁⟩.
- External verification (VAL): Every step is validated with the classic VAL plan validator; feedback can be binary (valid/invalid) or detailed (which precondition/effect failed). Detailed feedback yielded the strongest gains.
- Two-stage optimization:
- Stage-1 optimizes the reasoning chains (penalizing state-transition errors);
- Stage-2 optimizes end-task planning accuracy.
How Good is it? Benchmarks
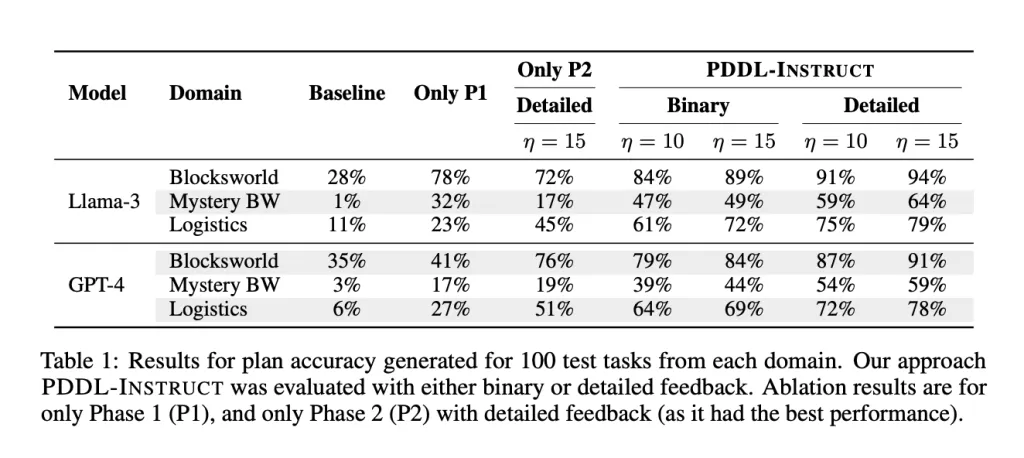
Evaluation follows PlanBench—Blocksworld, Mystery Blocksworld (predicate names obfuscated to break pattern-matching), and Logistics—established stress tests where generic LLMs historically underperform on plan generation. The authors highlight that Mystery Blocksworld is particularly challenging; prior studies often report <5% validity without tool support.
- Blocksworld: up to 94% valid plans with Llama-3-8B under PDDL-INSTRUCT.
- Mystery Blocksworld: large relative gains; the paper reports dramatic improvement versus a near-zero baseline (reported as orders-of-magnitude, e.g., 64× in their summary figures/tables).
- Logistics: substantial increases in valid plans.
Across domains, the research team showcase up to 66% absolute improvement over untuned baselines. Detailed validator feedback outperforms binary signals, and longer feedback budgets further help.
Summary
PDDL-INSTRUCT shows that coupling logical chain-of-thought with external plan validation can materially improve LLM planning, but its current scope is classical PDDL domains (Blocksworld, Mystery Blocksworld, Logistics) and relies on VAL as an external oracle; the reported gains—e.g., 94% valid plans on Blocksworld and large relative improvements on Mystery Blocksworld with Llama-3-8B—demonstrate a viable path for neuro-symbolic training where reasoning steps are grounded in formal semantics and checked automatically, suggesting immediate utility for agent pipelines that can tolerate a verifier in the loop while longer-horizon, temporal/numeric, and cost-sensitive planning remain open extensions.
Check out the PAPER. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.






