
Meta researchers introduced a method that compresses repeated reasoning patterns into short, named procedures—“behaviors”—and then conditions models to use them at inference or distills them via fine-tuning. The result: up to 46% fewer reasoning tokens on MATH while matching or improving accuracy, and up to 10% accuracy gains in a self-improvement setting on AIME, without changing model weights. The work frames this as procedural memory for LLMs—how to reason, not just what to recall—implemented with a curated, searchable “behavior handbook.”
What problem does this solve?
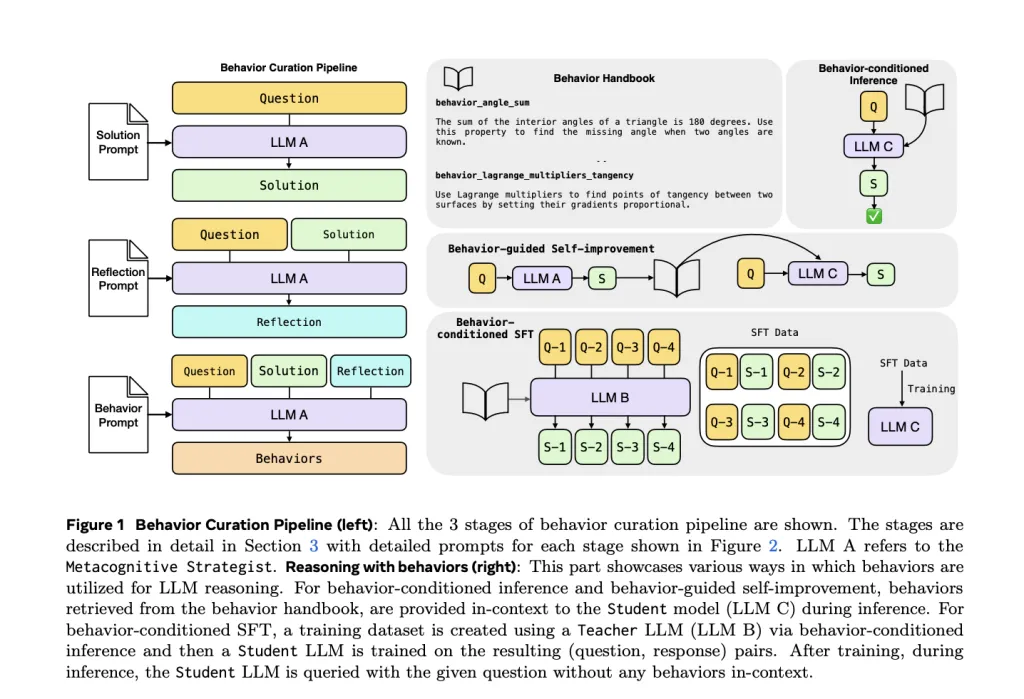
Long chain-of-thought (CoT) traces repeatedly re-derive common sub-procedures (e.g., inclusion–exclusion, base conversions, geometric angle sums). That redundancy burns tokens, adds latency, and can crowd out exploration. Meta’s idea is to abstract recurring steps into concise, named behaviors (name + one-line instruction) recovered from prior traces via an LLM-driven reflection pipeline, then reuse them during future reasoning. On math benchmarks (MATH-500; AIME-24/25), this reduces output length substantially while preserving or improving solution quality.
How does the pipeline work?
Three roles, one handbook:
- Metacognitive Strategist (R1-Llama-70B):
- solves a problem to produce a trace, 2) reflects on the trace to identify generalizable steps, 3) emits behaviors as
(behavior_name → instruction)entries. These populate a behavior handbook (procedural memory).
- solves a problem to produce a trace, 2) reflects on the trace to identify generalizable steps, 3) emits behaviors as
- Teacher (LLM B): generates behavior-conditioned responses used to build training corpora.
- Student (LLM C): consumes behaviors in-context (inference) or is fine-tuned on behavior-conditioned data.
Retrieval is topic-based on MATH and embedding-based (BGE-M3 + FAISS) on AIME.
Prompts: The team provides explicit prompts for solution, reflection, behavior extraction, and behavior-conditioned inference (BCI). In BCI, the model is instructed to reference behaviors explicitly in its reasoning, encouraging consistently short, structured derivations.
What are the evaluation modes?
- Behavior-Conditioned Inference (BCI): Retrieve K relevant behaviors and prepend them to the prompt.
- Behavior-Guided Self-Improvement: Extract behaviors from a model’s own earlier attempts and feed them back as hints for revision.
- Behavior-Conditioned SFT (BC-SFT): Fine-tune students on teacher outputs that already follow behavior-guided reasoning, so the behavior usage becomes parametric (no retrieval at test time).
Key results (MATH, AIME-24/25)
- Token efficiency: On MATH-500, BCI reduces reasoning tokens by up to 46% versus the same model without behaviors, while matching or improving accuracy. This holds for both R1-Llama-70B and Qwen3-32B students across token budgets (2,048–16,384).
- Self-improvement gains: On AIME-24, behavior-guided self-improvement beats a critique-and-revise baseline at nearly every budget, with up to 10% higher accuracy as budgets increase, indicating better test-time scaling of accuracy (not just shorter traces).
- BC-SFT quality lift: Across Llama-3.1-8B-Instruct, Qwen2.5-14B-Base, Qwen2.5-32B-Instruct, and Qwen3-14B, BC-SFT consistently outperforms (accuracy) standard SFT and the original base across budgets, while remaining more token-efficient. Importantly, the advantage is not explained by an easier training corpus: teacher correctness rates in the two training sets (original vs. behavior-conditioned) are close, yet BC-SFT students generalize better on AIME-24/25.
Why does this work?
The handbook stores procedural knowledge (how-to strategies), distinct from classic RAG’s declarative knowledge (facts). By converting verbose derivations into short, reusable steps, the model skips re-derivation and reallocates compute to novel subproblems. Behavior prompts serve as structured hints that bias the decoder toward efficient, correct trajectories; BC-SFT then internalizes these trajectories so that behaviors are implicitly invoked without prompt overhead.
What’s inside a “behavior”?
Behaviors range from domain-general reasoning moves to precise mathematical tools, e.g.,
behavior_inclusion_exclusion_principle: avoid double counting by subtracting intersections;behavior_translate_verbal_to_equation: formalize word problems systematically;behavior_distance_from_point_to_line: apply |Ax+By+C|/√(A²+B²) for tangency checks.
During BCI, the student explicitly cites behaviors when they’re used, making traces auditable and compact.
Retrieval and cost considerations
On MATH, behaviors are retrieved by topic; on AIME, top-K behaviors are selected via BGE-M3 embeddings and FAISS. While BCI introduces extra input tokens (the behaviors), input tokens are pre-computable and non-autoregressive, and are often billed cheaper than output tokens on commercial APIs. Since BCI shrinks output tokens, the overall cost can drop while latency improves. BC-SFT eliminates retrieval at test time entirely.

Summary
Meta’s behavior-handbook approach operationalizes procedural memory for LLMs: it abstracts recurring reasoning steps into reusable “behaviors,” applies them via behavior-conditioned inference or distills them with BC-SFT, and empirically delivers up to 46% fewer reasoning tokens with accuracy that holds or improves (≈10% gains in self-correction regimes). The method is straightforward to integrate—an index, a retriever, optional fine-tuning—and surfaces auditable traces, though scaling beyond math and managing a growing behavior corpus remain open engineering problems.
Check out the PAPER. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.






