
A team of researchers associated with Amazon has released A-Evolve, a universal infrastructure designed to automate the development of autonomous AI agents. The framework aims to replace the ‘manual harness engineering’ that currently defines agent development with a systematic, automated evolution process.
The project is being described as a potential ‘PyTorch moment’ for agentic AI. Just as PyTorch moved deep learning away from manual gradient calculations, A-Evolve seeks to move agent design away from hand-tuned prompts and toward a scalable framework where agents improve their own code and logic through iterative cycles.
The Problem: The Manual Tuning Bottleneck
In current workflows, software and AI engineers building autonomous agents often find themselves in a loop of manual trial and error. When an agent fails a task—such as resolving a GitHub issue on SWE-bench—the developer must manually inspect logs, identify the logic failure, and then rewrite the prompt or add a new tool.
A-Evolve is built to automate this loop. The framework’s core premise is that an agent can be treated as a collection of mutable artifacts that evolve based on structured feedback from their environment. This can transform a basic ‘seed’ agent into a high-performing one with ‘zero human intervention,‘ a goal achieved by delegating the tuning process to an automated engine.
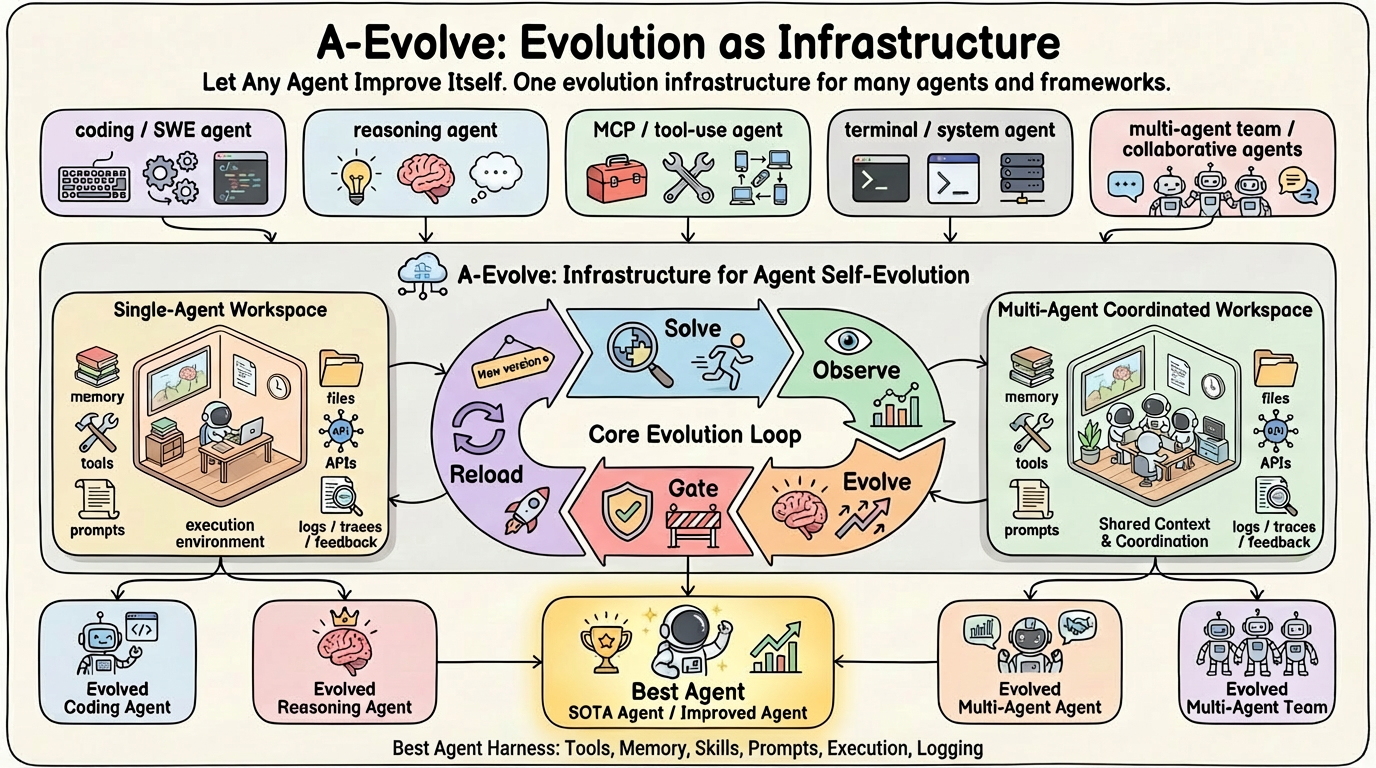
The Architecture: The Agent Workspace and Manifest
A-Evolve introduces a standardized directory structure called the Agent Workspace. This workspace defines the agent’s ‘DNA’ through five critical components:
manifest.yaml: The central configuration file that defines the agent’s metadata, entry points, and operational parameters.prompts/: The system messages and instructional logic that guide the LLM’s reasoning.skills/: Reusable code snippets or discrete functions the agent can learn to execute.tools/: Configurations for external interfaces and APIs.memory/: Episodic data and historical context used to inform future actions.
The Mutation Engine operates directly on these files. Rather than just changing a prompt in memory, the engine modifies the actual code and configuration files within the workspace to improve performance.
The Five-Stage Evolution Loop
The framework’s precision lies in its internal logic, which follows a structured five-stage loop to ensure that improvements are both effective and stable:
- Solve: The agent attempts to complete tasks within the target environment (BYOE).
- Observe: The system generates structured logs and captures benchmark feedback.
- Evolve: The Mutation Engine analyzes the observations to identify failure points and modifies the files in the Agent Workspace.
- Gate: The system validates the new mutation against a set of fitness functions to ensure it doesn’t cause regressions.
- Reload: The agent is re-initialized with the updated workspace, and the cycle begins again.
To ensure reproducibility, A-Evolve integrates with Git. Every mutation is automatically git-tagged (e.g., evo-1, evo-2). If a mutation fails the ‘Gate’ stage or shows poor performance in the next cycle, the system can automatically roll back to the last stable version.
‘Bring Your Own’ (BYO) Modularity
A-Evolve is designed as a modular framework rather than a specific agent model. This allows AI professionals to swap components based on their specific needs:
- Bring Your Own Agent (BYOA): Support for any architecture, from basic ReAct loops to complex multi-agent systems.
- Bring Your Own Environment (BYOE): Compatibility with diverse domains, including software engineering sandboxes or cloud-based CLI environments.
- Bring Your Own Algorithm (BYO-Algo): Flexibility to use different evolution strategies, such as LLM-driven mutation or Reinforcement Learning (RL).
Benchmark Performance
The A-EVO-Lab team has tested the framework using a base Claude-series model across several rigorous benchmarks. The results show that automated evolution can drive agents toward top-tier performance:
- MCP-Atlas: Reached 79.4% (#1), a +3.4pp increase. This benchmark specifically evaluates tool-calling capabilities using the Model Context Protocol (MCP) across multiple servers.
- SWE-bench Verified: Achieved 76.8% (~#5), a +2.6pp improvement in resolving real-world software bugs.
- Terminal-Bench 2.0: Reached 76.5% (~#7), representing a +13.0pp increase in command-line proficiency within Dockerized environments.
- SkillsBench: Hit 34.9% (#2), a +15.2pp gain in autonomous skill discovery.
In the MCP-Atlas test, the system evolved a generic 20-line prompt with no initial skills into an agent with five targeted, newly-authored skills that allowed it to reach the top of the leaderboard.
Implementation
A-Evolve is designed to be integrated into existing Python workflows. You provide a Base Agent. A-Evolve returns a SOTA Agent. 3 lines of code. 0 hours of manual harness engineering. One infra, any domain, any evolution algorithm. The following snippet illustrates how to initialize the evolution process:
import agent_evolve as ae
evolver = ae.Evolver(agent="./my_agent", benchmark="swe-verified")
results = evolver.run(cycles=10)Key Takeaways
- From Manual to Automated Tuning: A-Evolve shifts the development paradigm from ‘manual harness engineering’ (hand-tuning prompts and tools) to an automated evolution process, allowing agents to self-improve their own logic and code.
- The ‘Agent Workspace’ Standard: The framework treats agents as a standardized directory containing five core components—
manifest.yaml, prompts, skills, tools, and memory—providing a clean, file-based interface for the Mutation Engine to modify. - Closed-Loop Evolution with Git: A-Evolve utilizes a five-stage loop (Solve, Observe, Evolve, Gate, Reload) to ensure stable improvements. Every mutation is git-tagged (e.g.,
evo-1), allowing for full reproducibility and automatic rollbacks if a mutation regresses. - Agnostic ‘Bring Your Own’ Infrastructure: The framework is highly modular, supporting BYOA (Agent), BYOE (Environment), and BYO-Algo (Algorithm). This allows developers to use any model or evolution strategy across any specialized domain.
- Proven SOTA Gains: The infrastructure has already demonstrated State-of-the-Art performance, propelling agents to #1 on MCP-Atlas (79.4%) and high rankings on SWE-bench Verified (~#5) and Terminal-Bench 2.0 (~#7) with zero manual intervention.
Check out the Repo. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.







