
Anthropic released Claude Haiku 4.5, a latency-optimized “small” model that delivers similar levels of coding performance to Claude Sonnet 4 while running more than twice as fast at one-third the cost. The model is immediately available via Anthropic’s API and in partner catalogs on Amazon Bedrock and Google Cloud Vertex AI. Pricing is $1/MTok input and $5/MTok output. Anthropic positions Haiku 4.5 as a drop-in replacement for Haiku 3.5 and Sonnet 4 in cost-sensitive, interactive workloads.
Positioning and lineup
Haiku 4.5 targets real-time assistants, customer-support automations, and pair-programming where tight latency budgets and throughput dominate. It surpasses Sonnet 4 on “computer use” tasks—the GUI/browser manipulation underpinning products like Claude for Chrome—and is described as materially improving responsiveness in Claude Code for multi-agent projects and rapid prototyping. Anthropic makes clear that Sonnet 4.5 remains the frontier model and “the best coding model in the world,” while Haiku 4.5 offers near-frontier performance with greater cost-efficiency. A recommended pattern is Sonnet 4.5 for multi-step planning and parallel execution by a pool of Haiku 4.5 workers.
Availability, identifiers, and pricing
From day one, developers can call the model (claude-haiku-4-5) on Anthropic’s API. Anthropic also states availability on Amazon Bedrock and Vertex AI; model catalogs may update region coverage and IDs over time, but the company confirms cloud availability in the launch post. The API price for Haiku 4.5 is $1/MTok (input) and $5/MTok (output), with prompt-caching listed at $1.25/MTok write and $0.10/MTok read.
Benchmarks
Anthropic summarizes results across standard and agentic suites and includes methodology details to qualify the numbers:
- SWE-bench Verified: simple scaffold with two tools (bash, file edits), 73.3% averaged over 50 trials, no test-time compute, 128K thinking budget, default sampling. Includes a minor prompt addendum encouraging extensive tool use and writing tests first.
- Terminal-Bench: Terminus-2 agent, average over 11 runs (6 without thinking, 5 with 32K thinking budget).
- OSWorld-Verified: 100 max steps, averaged across 4 runs with a 128K total thinking budget and 2K per-step configuration.
- AIME / MMMLU: averages over multiple runs using default sampling and 128K thinking budgets.
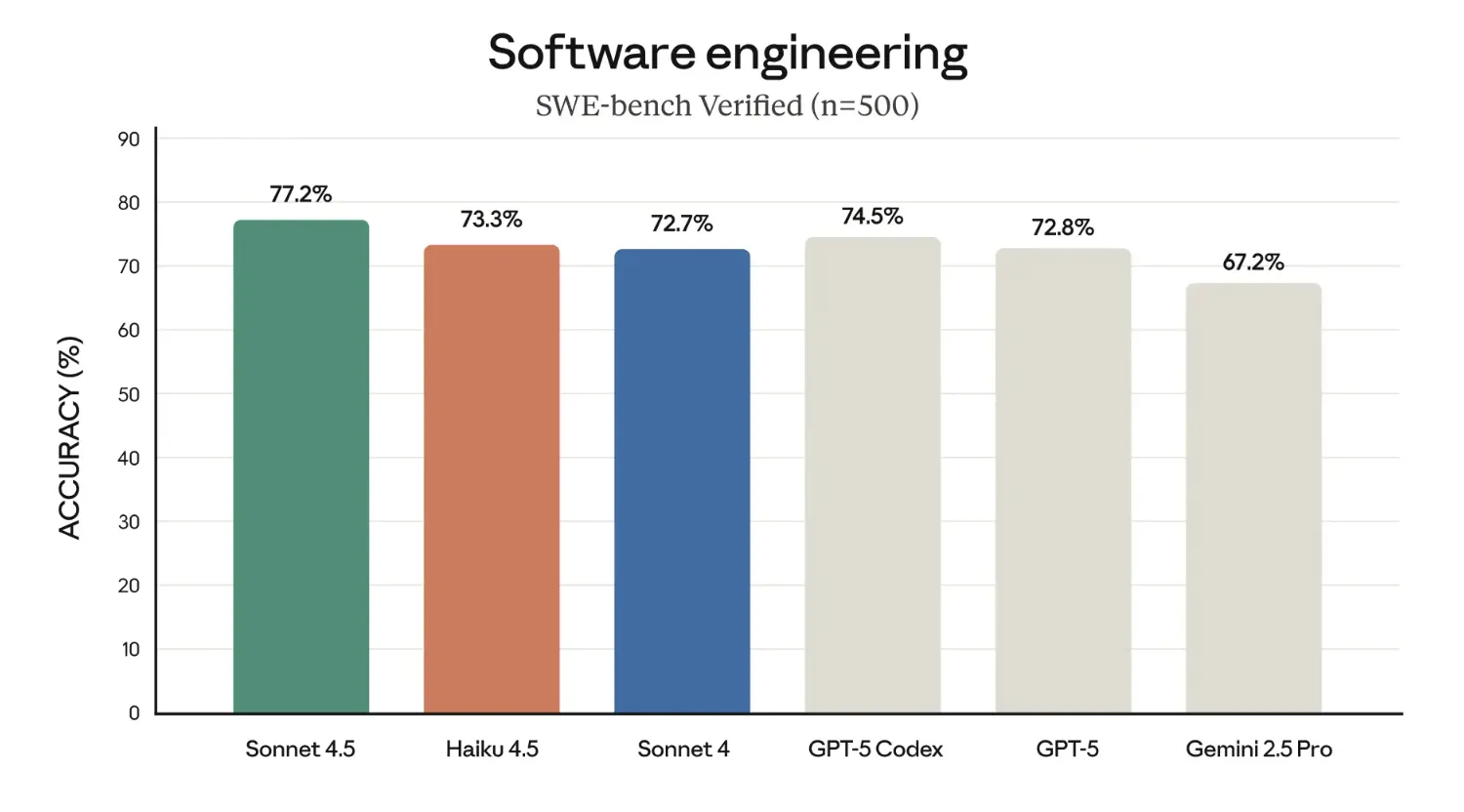
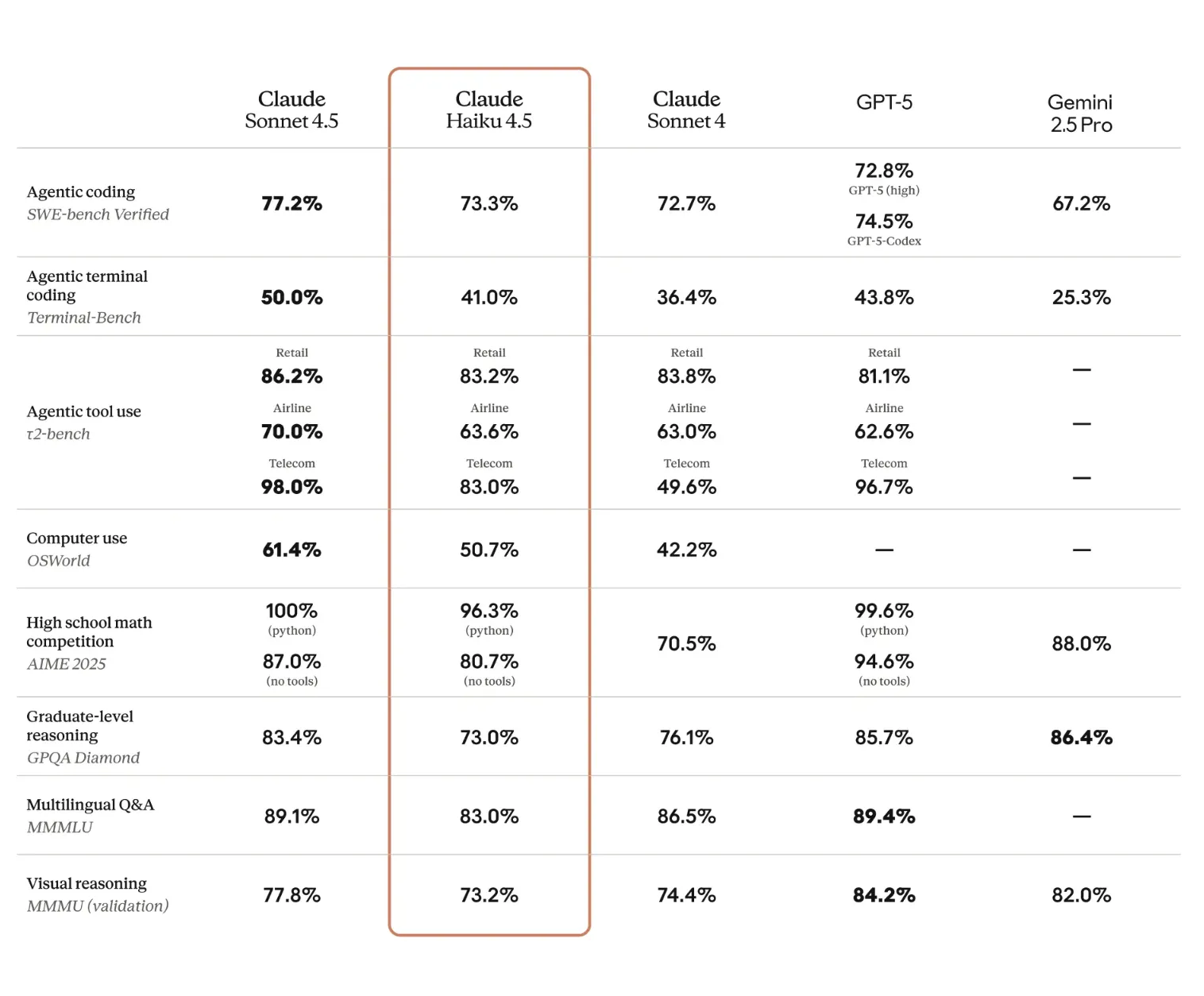
The post emphasizes coding parity with Sonnet 4 and computer-use gains relative to Sonnet 4 under these scaffolds. Users should replicate with their own orchestration, tool stacks, and thinking budgets before generalizing.
Key Takeaways
- Haiku 4.5 delivers Sonnet-4-level coding performance at one-third the cost and more than twice the speed.
- It surpasses Sonnet 4 on computer-use tasks, improving responsiveness in Claude for Chrome and multi-agent flows in Claude Code.
- Recommended orchestration: use Sonnet 4.5 for multi-step planning and parallelize execution with multiple Haiku 4.5 workers.
- Pricing is $1/$5 per million input/output tokens; available via Claude API, Amazon Bedrock, and Google Cloud Vertex AI.
- Released under ASL-2 with a lower measured misalignment rate than Sonnet 4.5 and Opus 4.1 in Anthropic’s tests.
Anthropic’s positioning of Claude Haiku 4.5 is strategically sound: by delivering similar levels of coding performance to Claude Sonnet 4 at one-third the cost and more than twice the speed, while surpassing Sonnet 4 on computer use, the company gives devs a clean planner–executor split—Sonnet 4.5 for multi-step planning and a pool of Haiku 4.5 workers for parallel execution—without forcing architectural changes (“drop-in replacement” across API, Amazon Bedrock, Vertex AI). The ASL-2 release, coupled with a documented lower misalignment rate than Sonnet 4.5 and Opus 4.1, lowers the friction for enterprise rollout where safety gates and cost envelopes dominate deployment math.
Check out the Technical details, system card, model page, and documentation . Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.



")



