
The Baidu Qianfan Team introduced Qianfan-OCR, a 4B-parameter end-to-end model designed to unify document parsing, layout analysis, and document understanding within a single vision-language architecture. Unlike traditional multi-stage OCR pipelines that chain separate modules for layout detection and text recognition, Qianfan-OCR performs direct image-to-Markdown conversion and supports prompt-driven tasks like table extraction and document question answering.
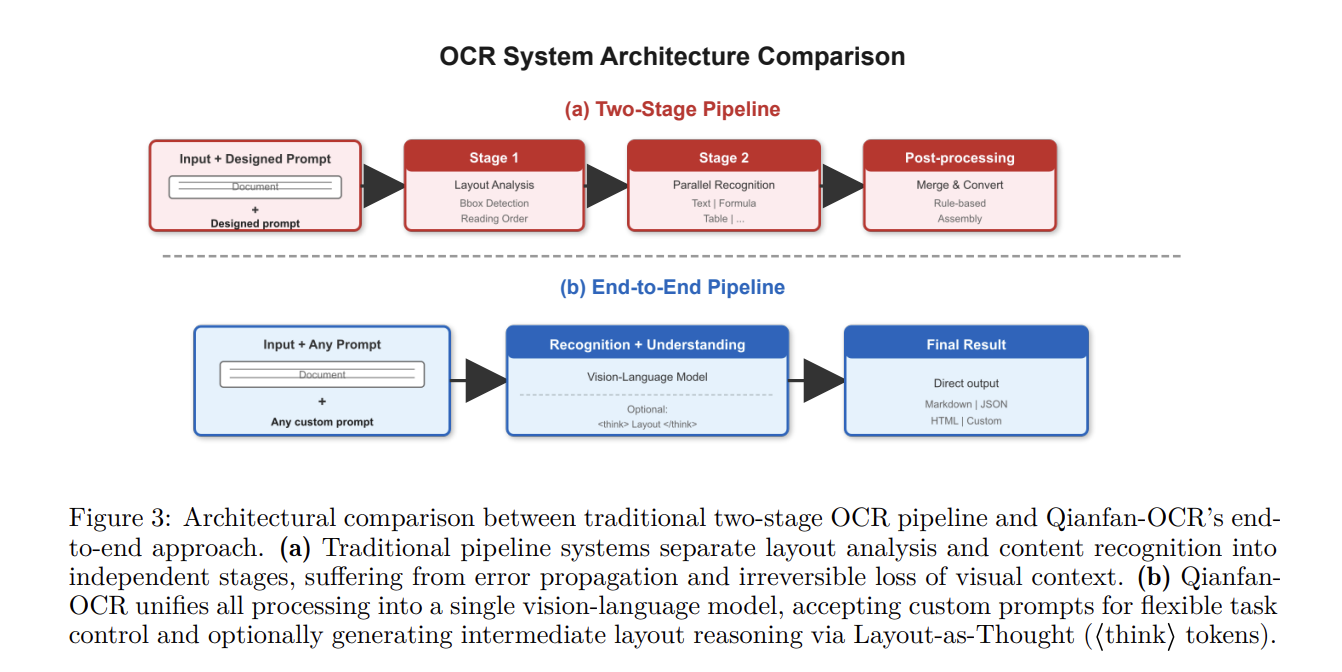
Architecture and Technical Specifications
Qianfan-OCR utilizes the multimodal bridging architecture from the Qianfan-VL framework. The system consists of three primary components:
- Vision Encoder (Qianfan-ViT): Employs an Any Resolution design that tiles images into 448 x 448 patches. It supports variable-resolution inputs up to 4K, producing up to 4,096 visual tokens per image to maintain spatial resolution for small fonts and dense text.
- Cross-Modal Adapter: A lightweight two-layer MLP with GELU activation that projects visual features into the language model’s embedding space.
- Language Model Backbone (Qwen3-4B): A 4.0B-parameter model with 36 layers and a native 32K context window. It utilizes Grouped-Query Attention (GQA) to reduce KV cache memory usage by 4x.
‘Layout-as-Thought’ Mechanism
The main feature of the model is Layout-as-Thought, an optional thinking phase triggered by
- Functional Utility: This process recovers explicit layout analysis capabilities (element localization and type classification) often lost in end-to-end paradigms.
- Performance Characteristics: Evaluation on OmniDocBench v1.5 indicates that enabling the thinking phase provides a consistent advantage on documents with high “layout label entropy”—those containing heterogeneous elements like mixed text, formulas, and diagrams.
- Efficiency: Bounding box coordinates are represented as dedicated special tokens (
Empirical Performance and Benchmarks
Qianfan-OCR was evaluated against both specialized OCR systems and general vision-language models (VLMs).
Document Parsing and General OCR
The model ranks first among end-to-end models on several key benchmarks:
- OmniDocBench v1.5: Achieved a score of 93.12, surpassing DeepSeek-OCR-v2 (91.09) and Gemini-3 Pro (90.33).
- OlmOCR Bench: Scored 79.8, leading the end-to-end category.
- OCRBench: Achieved a score of 880, ranking first among all tested models.
On public KIE benchmarks, Qianfan-OCR achieved the highest average score (87.9), outperforming significantly larger models.
| Model | Overall Mean (KIE) | OCRBench KIE | Nanonets KIE (F1) |
| Qianfan-OCR (4B) | 87.9 | 95.0 | 86.5 |
| Qwen3-4B-VL | 83.5 | 89.0 | 83.3 |
| Qwen3-VL-235B-A22B | 84.2 | 94.0 | 83.8 |
| Gemini-3.1-Pro | 79.2 | 96.0 | 76.1 |
Document Understanding
Comparative testing revealed that two-stage OCR+LLM pipelines often fail on tasks requiring spatial reasoning. For instance, all tested two-stage systems scored 0.0 on CharXiv benchmarks, as the text extraction phase discards the visual context (axis relationships, data point positions) necessary for chart interpretation.
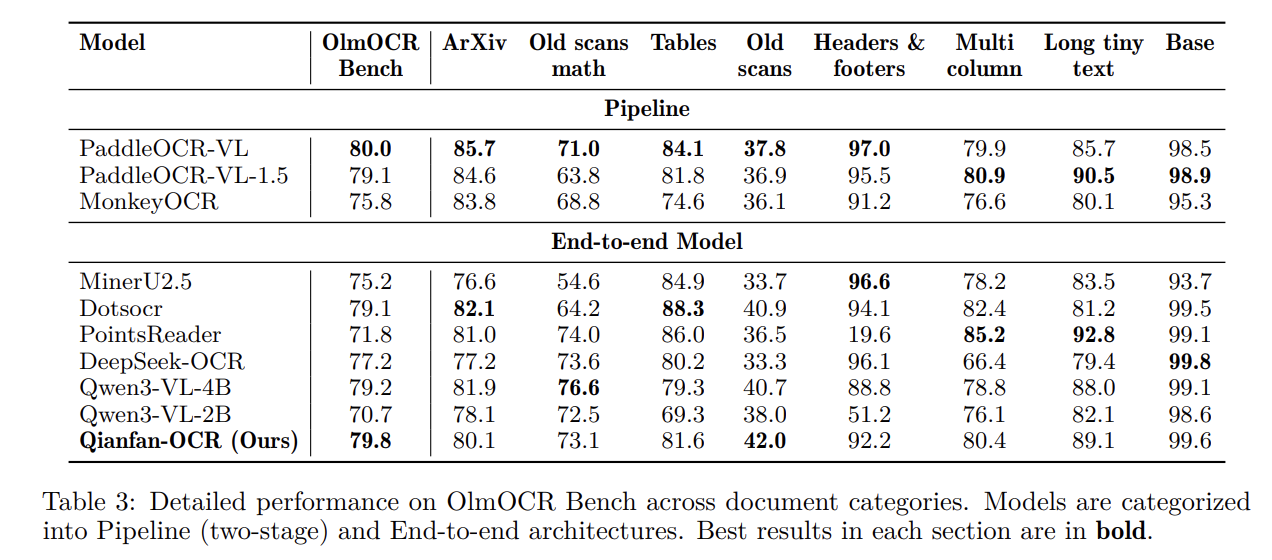
Deployment and Inference
Inference efficiency was measured in Pages Per Second (PPS) using a single NVIDIA A100 GPU.
- Quantization: With W8A8 (AWQ) quantization, Qianfan-OCR achieved 1.024 PPS, a 2x speedup over the W16A16 baseline with negligible accuracy loss.
- Architecture Advantage: Unlike pipeline systems that rely on CPU-based layout analysis—which can become a bottleneck—Qianfan-OCR is GPU-centric. This avoids inter-stage processing delays and allows for efficient large-batch inference.
Check out Paper, Repo and Model on HF. Also, feel free to follow us on Twitter and don’t forget to join our 120k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.



 | 1-Gallon + Splash Proof")



