
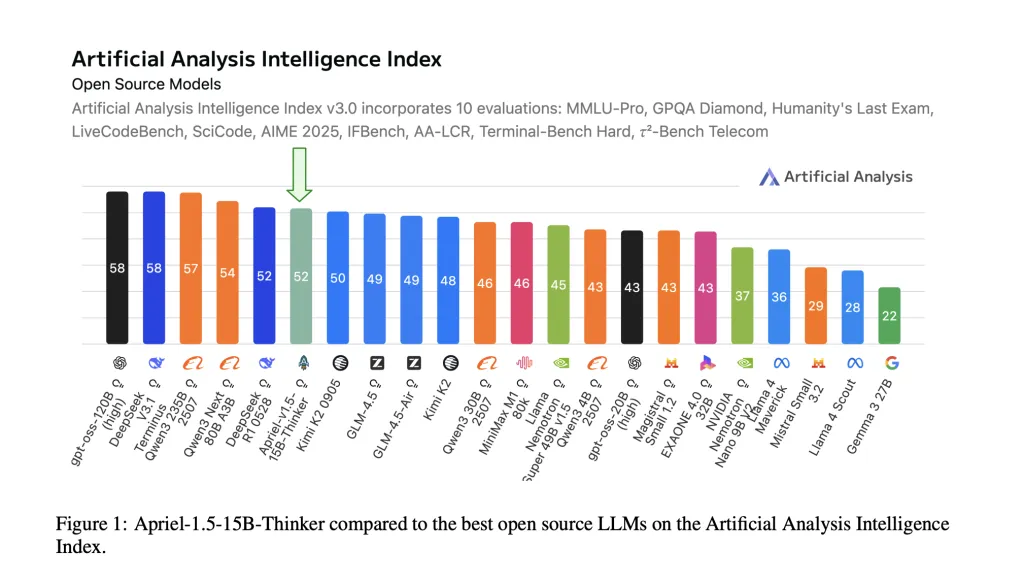
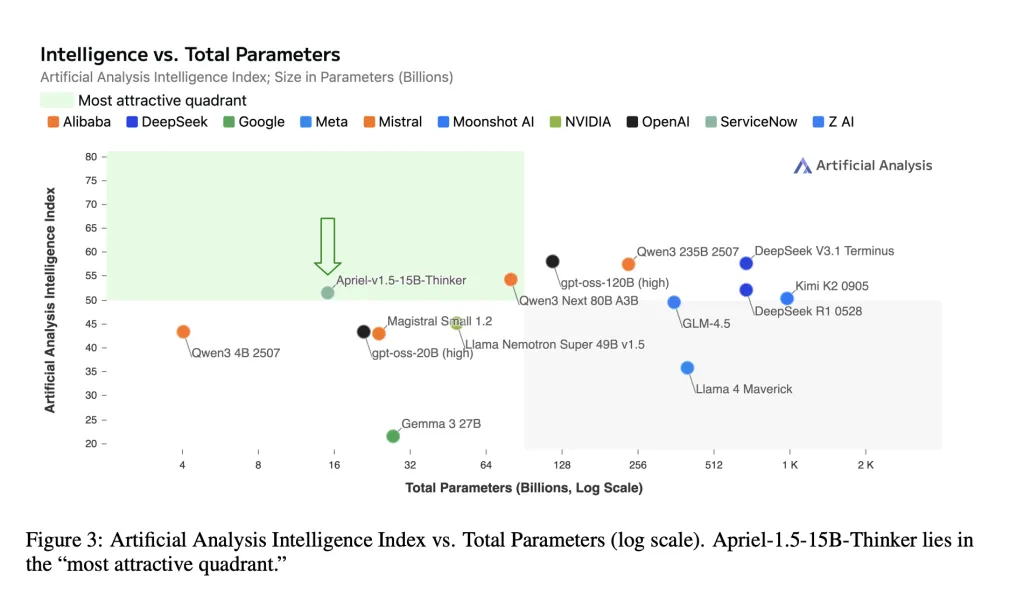
ServiceNow AI Research Lab has released Apriel-1.5-15B-Thinker, a 15-billion-parameter open-weights multimodal reasoning model trained with a data-centric mid-training recipe—continual pretraining followed by supervised fine-tuning—without reinforcement learning or preference optimization. The model attains an Artificial Analysis Intelligence Index score of 52 with 8x cost savings compared to SOTA. The checkpoint ships under an MIT license on Hugging Face.
So, What’s new in it for me?
- Frontier-level composite score at small scale. The model reports Artificial Analysis Intelligence Index (AAI) = 52, matching DeepSeek-R1-0528 on that combined metric while being dramatically smaller. AAI aggregates 10 third-party evaluations (MMLU-Pro, GPQA Diamond, Humanity’s Last Exam, LiveCodeBench, SciCode, AIME 2025, IFBench, AA-LCR, Terminal-Bench Hard, τ²-Bench Telecom).
- Single-GPU deployability. The model card states the 15B checkpoint “fits on a single GPU,” targeting on-premises and air-gapped deployments with fixed memory and latency budgets.
- Open weights and reproducible pipeline. Weights, training recipe, and evaluation protocol are public for independent verification.
Ok! I got it but what is it’s training mechanism?
Base and upscaling. Apriel-1.5-15B-Thinker starts from Mistral’s Pixtral-12B-Base-2409 multimodal decoder-vision stack. The research team applies depth upscaling—increasing decoder layers from 40→48—then projection-network realignment to align the vision encoder with the enlarged decoder. This avoids pretraining from scratch while preserving single-GPU deployability.
CPT (Continual Pretraining). Two stages: (1) mixed text+image data to build foundational reasoning and document/diagram understanding; (2) targeted synthetic visual tasks (reconstruction, matching, detection, counting) to sharpen spatial and compositional reasoning. Sequence lengths extend to 32k and 16k tokens respectively, with selective loss placement on response tokens for instruction-formatted samples.
SFT (Supervised Fine-Tuning). High-quality, reasoning-trace instruction data for math, coding, science, tool use, and instruction following; two additional SFT runs (stratified subset; longer-context) are weight-merged to form the final checkpoint. No RL (reinforcement learning) or RLAIF (reinforcement learning from AI feedback).
Data note. ~25% of the depth-upscaling text mix derives from NVIDIA’s Nemotron collection.
O’ Wow! Tell me about it’s results then?
Key text benchmarks (pass@1 / accuracy).
- AIME 2025 (American Invitational Mathematics Examination 2025): 87.5–88%
- GPQA Diamond (Graduate-Level Google-Proof Question Answering, Diamond split): ≈71%
- IFBench (Instruction-Following Benchmark): ~62
- τ²-Bench (Tau-squared Bench) Telecom: ~68
- LiveCodeBench (functional code correctness): ~72.8
Using VLMEvalKit for reproducibility, Apriel scores competitively across MMMU / MMMU-Pro (Massive Multi-discipline Multimodal Understanding), LogicVista, MathVision, MathVista, MathVerse, MMStar, CharXiv, AI2D, BLINK, with stronger results on documents/diagrams and text-dominant math imagery.
Lets Summarize everything
Apriel-1.5-15B-Thinker demonstrates that careful mid-training (continual pretraining + supervised fine-tuning, no reinforcement learning) can deliver a 52 on the Artificial Analysis Intelligence Index (AAI) while remaining deployable on a single graphics processing unit. Reported task-level scores (for example, AIME 2025 ≈88, GPQA Diamond ≈71, IFBench ≈62, Tau-squared Bench Telecom ≈68) align with the model card and place the 15-billion-parameter checkpoint in the most cost-efficient band of current open-weights reasoners. For enterprises, that combination—open weights, reproducible recipe, and single-GPU latency—makes Apriel a practical baseline to evaluate before considering larger closed systems.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.


")




