 While Maintaining Benchmark Parity")
DeepSeek released DeepSeek-V3.2-Exp, an “intermediate” update to V3.1 that adds DeepSeek Sparse Attention (DSA)—a trainable sparsification path aimed at long-context efficiency. DeepSeek also reduced API prices by 50%+, consistent with the stated efficiency gains.
DeepSeek-V3.2-Exp keeps the V3/V3.1 stack (MoE + MLA) and inserts a two-stage attention path: (i) a lightweight “indexer” that scores context tokens; (ii) sparse attention over the selected subset.
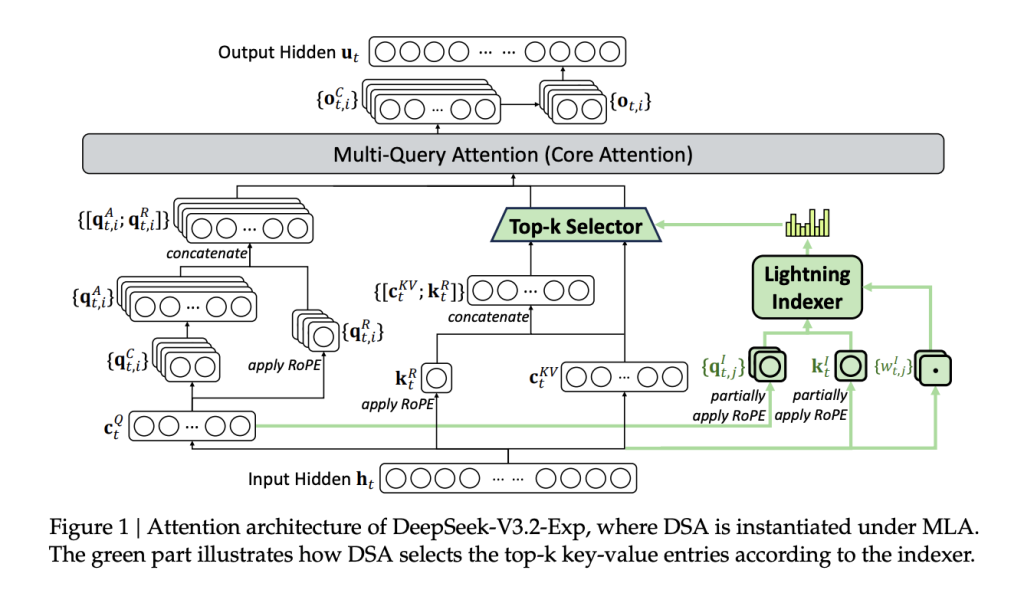
FP8 index → top-k selection → sparse core attention
DeepSeek Sparse Attention (DSA) splits the attention path into two compute tiers:
(1) Lightning indexer (FP8, few heads): For each query token
ℎ
𝑡
∈
𝑅
𝑑
h
t
∈R
d
, a lightweight scoring function computes index logits
𝐼
𝑡
,
𝑠
I
t,s
against preceding tokens
ℎ
𝑠
h
s
. It uses small indexer heads with a ReLU nonlinearity for throughput. Because this stage runs in FP8 and with few heads, its wall-time and FLOP cost are minor relative to dense attention.
(2) Fine-grained token selection (top-k): The system selects only the top-k=2048 key-value entries for each query and then performs standard attention only over that subset. This changes the dominant term from
𝑂
(
𝐿
2
)
O(L
2
) to
𝑂
(
𝐿
𝑘
)
O(Lk) with
𝑘
≪
𝐿
k≪L, while preserving the ability to attend to arbitrarily distant tokens when needed.
Training signal: The indexer is trained to imitate the dense model’s head-summed attention distribution via KL-divergence, first under a short dense warm-up (indexer learns targets while the main model is frozen), then during sparse training where gradients for the indexer remain separate from the main model’s language loss. Warm-up uses ~2.1B tokens; sparse stage uses ~943.7B tokens with top-k=2048, LR ~7.3e-6 for the main model.
Instantiation: DSA is implemented under MLA (Multi-head Latent Attention) in MQA mode for decoding so each latent KV entry is shared across query heads, aligning with the kernel-level requirement that KV entries be reused across queries for throughput.
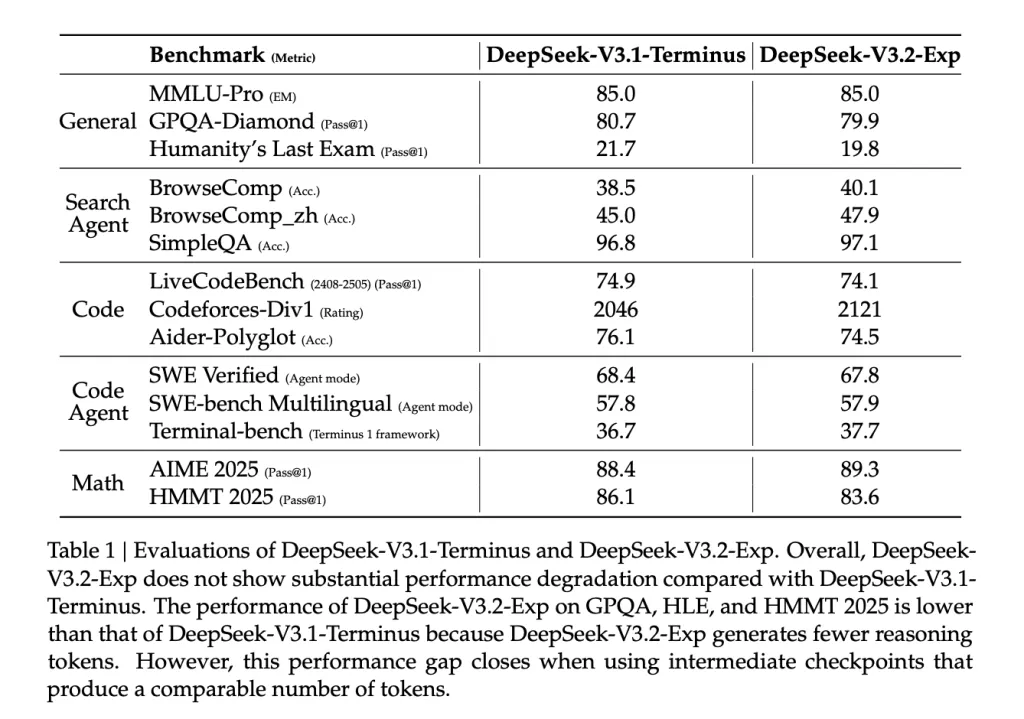
Lets Talk about it’s efficiency and accuracy
- Costs vs. position (128k): DeepSeek provides per-million-token cost curves for prefill and decode on H800 clusters (reference price $2/GPU-hour). Decode costs fall substantially with DSA; prefill also benefits via a masked MHA simulation at short lengths. While the exact 83% figure circulating on social media maps to “~6× cheaper decode at 128k,” treat it as DeepSeek-reported until third-party replication lands.
- Benchmark parity: The released table shows MMLU-Pro = 85.0 (unchanged), small movement on GPQA/HLE/HMMT due to fewer reasoning tokens, and flat/positive movement on agentic/search tasks (e.g., BrowseComp 40.1 vs 38.5). The authors note the gaps close when using intermediate checkpoints that produce comparable token counts.
- Operational signals: Day-0 support in SGLang and vLLM suggests the kernels and scheduler changes are production-aimed, not research-only. DeepSeek also references TileLang, DeepGEMM (indexer logits), and FlashMLA (sparse kernels) for open-source kernels.
- Pricing: DeepSeek says API prices were cut by 50%+, consistent with model-card messaging about efficiency and Reuters/TechCrunch coverage that the release targets lower long-context inference economics.
Summary
DeepSeek V3.2-Exp shows that trainable sparsity (DSA) can hold benchmark parity while materially improving long-context economics: official docs commit to 50%+ API price cuts, with day-0 runtime support already available, and community threads claim larger decode-time gains at 128k that warrant independent replication under matched batching and cache policies. The near-term takeaway for teams is simple: treat V3.2-Exp as a drop-in A/B for RAG and long-document pipelines where O(L2)O(L^2)O(L2) attention dominates costs, and validate end-to-end throughput/quality on your stack.
FAQs
1) What exactly is DeepSeek V3.2-Exp?
V3.2-Exp is an experimental, intermediate update to V3.1-Terminus that introduces DeepSeek Sparse Attention (DSA) to improve long-context efficiency.
2) Is it truly open source, and under what license?
Yes. The repository and model weights are licensed under MIT, per the official Hugging Face model card (License section).
3) What is DeepSeek Sparse Attention (DSA) in practice?
DSA adds a lightweight indexing stage to score/select a small set of relevant tokens, then runs attention only over that subset—yielding “fine-grained sparse attention” and reported long-context training/inference efficiency gains while keeping output quality on par with V3.1.
Check out the GitHub Page and Hugging Face Model Card. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.



")



