
Alibaba Cloud’s Qwen team unveiled Qwen3-ASR Flash, an all-in-one automatic speech recognition (ASR) model (available as API service) built upon the strong intelligence of Qwen3-Omni that simplifies multilingual, noisy, and domain-specific transcription without juggling multiple systems.
Key Capabilities
- Multilingual recognition: Supports automatic detection and transcription across 11 languages including English and Chinese, plus Arabic, German, Spanish, French, Italian, Japanese, Korean, Portuguese, Russian, and simplified Chinese (zh). That breadth positions Qwen3-ASR for global usage without separate models.
- Context injection mechanism: Users can paste arbitrary text—names, domain-specific jargon, even nonsensical strings—to bias transcription. This is especially powerful in scenarios rich in idioms, proper nouns, or evolving lingo.
- Robust audio handling: Maintains performance in noisy environments, low-quality recordings, far-field input (e.g., distance mics), and multimedia vocals like songs or raps. Reported Word Error Rate (WER) remains under 8%, which is technically impressive for such diverse inputs.
- Single-model simplicity: Eliminates complexity of maintaining different models for languages or audio contexts—one model with an API Service to rule them all.
Use cases span edtech platforms (lecture capture, multilingual tutoring), media (subtitling, voice-over), and customer service (multilingual IVR or support transcription).
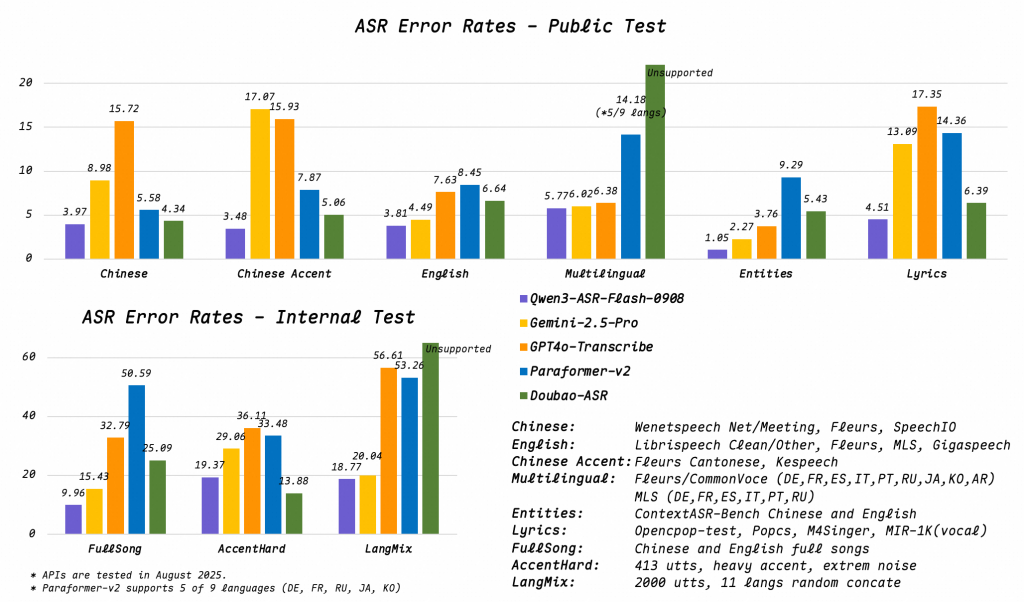
Technical Assessment
- Language Detection + Transcription
Automatic language detection lets the model determine the language before transcribing—crucial for mixed-language environments or passive audio capture. This reduces the need for manual language selection and improves usability. - Context Token Injection
Pasting text as “context” biases recognition toward expected vocabulary. Technically, this could operate via prefix tuning or prefix-injection—embedding context in the input stream to influence decoding. It’s a flexible way to adapt to domain-specific lexicons without re-training the model. - WER < 8% Across Complex Scenarios
Holding sub-8% WER across music, rap, background noise, and low-fidelity audio puts Qwen3-ASR in the upper echelon of open recognition systems. For comparison, robust models on clean read speech target 3–5% WER, but performance typically degrades significantly in noisy or musical contexts. - Multilingual Coverage
Supporting 11 languages, including divergence into logographic Chinese and languages with varying phonotactics like Arabic and Japanese, suggests substantial multilingual training data and cross-lingual modeling capacity. Handling both tonal (Mandarin) and non-tonal languages is non-trivial. - Single-Model Architecture
Operationally elegant: deploy one model for all tasks. This reduces ops burden—no need to swap or select models dynamically. Everything runs in a unified ASR pipeline with built-in language detection.
Deployment and Demo
The Hugging Face Space for Qwen3-ASR provides a live interface: upload audio, optionally input context, and choose a language or use auto-detect. It is available as an API Service.
Conclusion
Qwen3-ASR Flash (available as an API Service) is a technically compelling, deploy-friendly ASR solution. It offers a rare combination: multilingual support, context-aware transcription, and noise-robust recognition—all in one model.
Check out the API Service, Technical details and Demo on Hugging Face. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.







