
NVIDIA has released Nemotron 3 Ultra, the largest model in its Nemotron 3 family. It targets a specific problem: long-running agents that plan, call tools, and reason across many turns. As agents run longer, token counts grow and inference cost climbs. Nemotron 3 Ultra is designed to keep accuracy high while making that inference faster and cheaper.
What is Nemotron 3 Ultra
Nemotron 3 Ultra is a 550 billion total parameter Mixture-of-Experts (MoE) model. Only 55 billion parameters are active per token. The MoE design improves accuracy per active parameter.
It uses a hybrid Mamba-Attention architecture instead of a pure Transformer. Mamba layers handle long sequences with sub-quadratic scaling. A few Attention layers are kept for precise recall over large contexts.
The model was pre-trained on 20 trillion text tokens. Context was then extended to 1 million tokens. It was post-trained using Supervised Fine-Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD).
NVIDIA team reports up to roughly 6x higher inference throughput than comparable open LLMs, at on-par accuracy.
The Architecture
The model has 108 layers and a model dimension of 8,192. It uses 64 query heads and only 2 key-value heads, which keeps the KV cache small. Each MoE layer holds 512 experts, with the top 22 activated per token.
Three design choices stand out:
- LatentMoE routes experts more efficiently. It buys more routed experts at fixed inference cost by trading away hidden-dimension width. NVIDIA team reports better accuracy per parameter than standard granular MoEs.
- Multi-Token Prediction (MTP) predicts several future tokens in one forward pass. It enables native speculative decoding for faster generation. Two MTP heads share parameters during training.
- NVFP4 pre-training uses the E2M1 4-bit datatype with two-dimensional block quantization on weights. NVIDIA team calls this the largest-scale demonstration of stable, accurate NVFP4 training to date.
The hybrid Mamba-Attention stack are quite important for agents. Mamba’s per-step decode cost stays constant as sequence length grows. That is why throughput gains widen on long, decode-heavy workloads.
Pretraining and the Data Release
Pretraining used a Warmup-Stable-Decay learning rate schedule over 20 trillion tokens. It was split into two phases. The first 15 trillion tokens biased for diversity. The final 5 trillion biased for high-quality data.
NVIDIA team also released new domain-specific pretraining datasets. These include 173 billion refreshed GitHub code tokens. In a Nemotron 3 Nano ablation, a synthetic legal set raised a proxy LegalBench average from 64.6 to 74.7. In a similar ablation, a Wiki-based fact-seeking set raised proxy SimpleQA from 40.2 to 50.2.
The post-training release is also large. NVIDIA adds 10 million new SFT samples and 1 million new RL tasks. It adds 15 new RL environments. Cumulative Nemotron open totals reach 50M SFT samples, 2M RL tasks, and 55 RL environments.
Training was not entirely smooth. NVIDIA documents two loss divergences and treats them as a useful engineering record. The first, near 8 trillion tokens, traced to moving output-layer gradient reduction from FP32 to BF16. The MTP gradient contribution was effectively lost in BF16’s 7 mantissa bits. Reverting to FP32 gradient reduction re-stabilized training.
The second divergence, near 16 trillion tokens, had no confirmed root cause. NVIDIA mitigated it by annealing the learning rate early. It then cut the total token horizon to 20 trillion tokens.
Post-Training: SFT, RLVR, and MOPD
The post-training pipeline runs SFT, then unified RLVR, then MOPD warmup, MOPD, and MTP Boosting. The whole loop can repeat for several cycles.
RLVR stands for Reinforcement Learning with Verifiable Reward. It trains across many environments at once: terminal use, software engineering, search, math, code, safety, and more. The reward in these settings is often sparse and environment-dependent.
MOPD is the main new post-training method. Mixed-environment RLVR dilutes the learning signal as the number of environments grows. To address this, NVIDIA team trained more than ten domain-specialized teacher models. Each teacher has its own training pipeline.
During MOPD, the student model generates its own rollouts across domains. Each rollout is scored by the matching teacher with dense, token-level guidance. This is a denser signal than RLVR’s sparse rewards. The process runs asynchronously, with rollout generation, teacher scoring, and student updates pipelined.
MOPD is also iterative. After one MOPD checkpoint, new teachers are initialized from the improved student. Their gains merge back into the next round. NVIDIA team ran two MOPD iterations for Nemotron 3 Ultra.
One practical caveat is worth noting. MOPD works best when student rollouts stay within the teacher’s support. A brief SFT warmup aligns the two distributions first. NVIDIA team found gains are smaller on self-contained reasoning tasks the student rarely samples.
Reasoning Effort Control
Nemotron 3 Ultra supports three reasoning modes: reasoning-off, regular, and medium-effort. The regular and medium modes also accept an inference-time budget control.
Medium-effort is the efficiency lever. NVIDIA team reports it uses about 2.5x fewer tokens than regular mode. The cost is roughly a 7% drop in accuracy. For high-volume agent steps, that trade can lower spend meaningfully.
The Benchmark Case
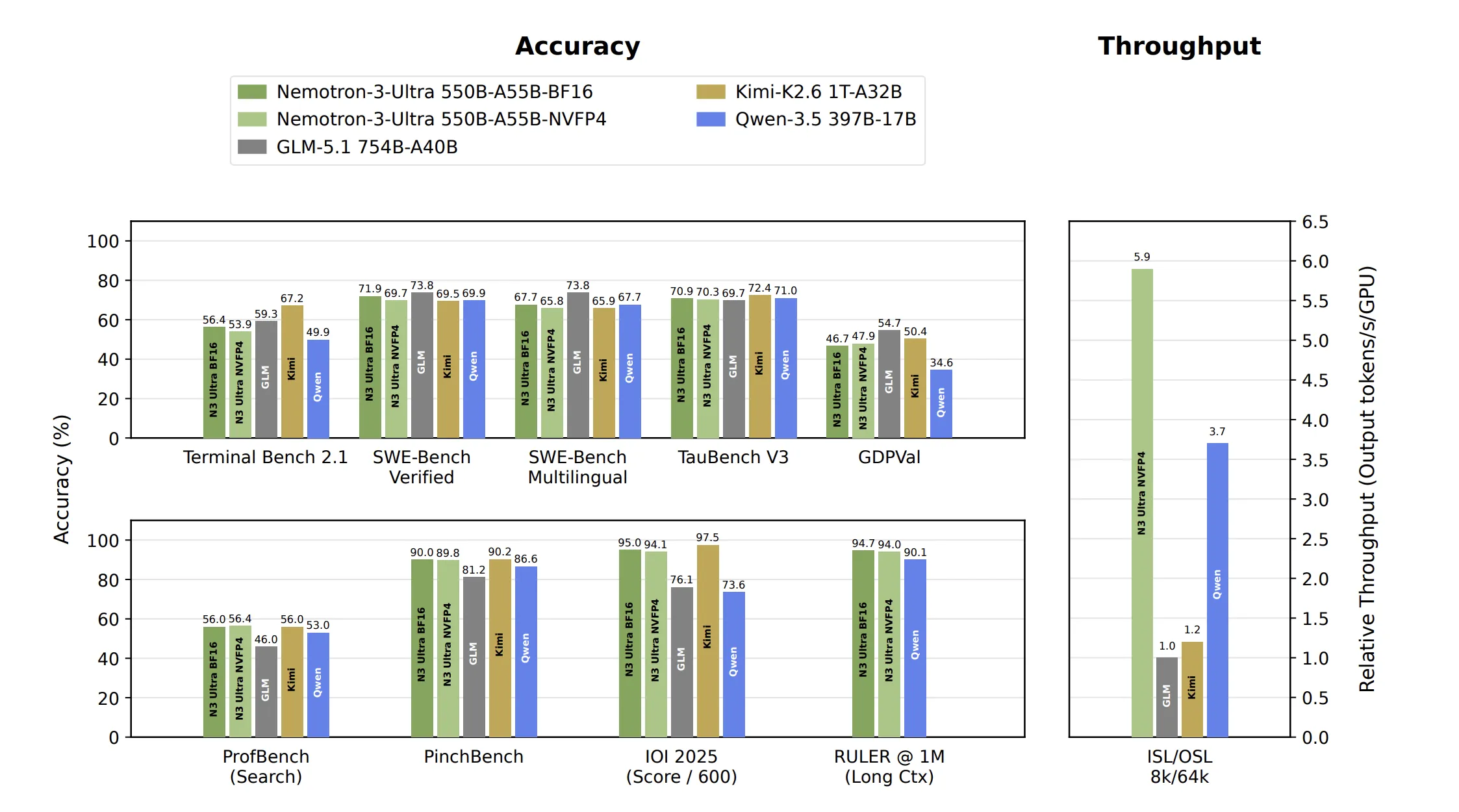
The comparisons in the NVIDIA’s research report use GLM-5.1 (754B), Kimi-K2.6 (1T), and Qwen-3.5 (397B), among others. The picture is competitive rather than dominant.
On agentic tasks, Nemotron 3 Ultra posts 90.0 on PinchBench and 56.0 on ProfBench (Search). NVIDIA team reserved both as held-out generalization gates, scored only once on the final model. It scores 71.9 on SWE-Bench Verified and 56.4 on Terminal Bench 2.1. On Terminal Bench, Kimi-K2.6 leads at 67.2.
On reasoning, it scores 570.0 on IOI 2025. NVIDIA team frames this as top-3-human-level competitive programming. On AA-Omniscience, it records the highest non-hallucination score in the set at 78.7. That suggests a lower tendency to answer when uncertain.
Long context holds up at scale. The model scores 94.7 on RULER at 1 million tokens. Several larger comparison models top out at 256K context.
On an 8K input / 64K output setting at NVFP4 on GB200, Nemotron 3 Ultra reaches 5.9x the throughput of GLM-5.1. It is 4.8x faster than Kimi-K2.6 and 1.6x faster than Qwen-3.5. Note: Nemotron’s numbers use TRT-LLM, while the others use vLLM.
The trade-off is visible on prefill-heavy work. On a 50K input / 2K output setting, it trails Qwen-3.5, because prefill cost tracks active parameters. NVIDIA team also reports up to 30% lower cost to task completion, from fewer tokens per turn on SWE-Bench and Terminal Bench.
NVIDIA team also stresses harness robustness. The model is trained under multiple agent harnesses per task type, not one. SWE-Bench Verified scores stay between 65% and 70.4% across Pi, OpenHands, Hermes, OpenCode, and Mini SWE Agent. The goal is consistent behavior regardless of deployment framework.
Quantization and Deployment
NVIDIA team ships a single NVFP4 checkpoint. On Blackwell it runs with native FP4 math. On Hopper it runs as W4A16, since Hopper lacks native FP4 tensor cores.
The final solution operates at 5.03 bits-per-element. It mixes NVFP4 routed experts with FP8 layers for shared experts and Mamba linears. Attention layers stay in BF16. NVIDIA team found accuracy saturated below this budget, so higher precision added no measurable gain.
The reduced weight footprint has a deployment benefit. The W4A16 path leaves room to fit MTP weights on a single 8-GPU H100 node. An FP8 checkpoint could not, without spanning two nodes.
Key Takeaways
- Nemotron 3 Ultra is a 550B open MoE (55B active) using a hybrid Mamba-Attention design for long-running agents.
- NVIDIA reports up to ~6x higher inference throughput than comparable open LLMs at on-par accuracy (5.9x vs GLM-5.1 on 8K/64K).
- It pairs a 1M-token context with the highest non-hallucination score in its comparison set (78.7 on AA-Omniscience).
- Post-training centers on Multi-teacher On-Policy Distillation (MOPD), distilling 10+ specialized teachers into one student.
- Weights, training data, and recipes ship openly under OpenMDW-1.1, with one NVFP4 checkpoint for Blackwell, Hopper, and Ampere.
Marktechpost’s Visual Explainer
NVIDIA Nemotron 3 Ultra
SLIDE 1 / 8
Curated by Marktechpost — AI/ML research & dev news for engineers and data scientists
Sources: NVIDIA Nemotron 3 Ultra technical report & blog · Verified Jun 4, 2026
Where to Use Nemotron 3 Ultra
Check out the Paper, Model Weights and Technical details. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us



")



